本文整理了长时间建图需要考虑问题以及常用的一些方法。内容主要参考自深蓝学院的激光slam课程。
Lifelong Mapping 的概念和应用
在长时间的建图过程中,基于图优化的 SLAM 的方法存在以下问题:PoseGraph 中的节点随着机器人走过的距离越来越多,以至于求解规模不断增大,影响优化效率。
而 Lifelong Mapping 的基本思想是实现机器人在进行导航过程中进行建图,使得 PoseGraph 的规模不能随着运行轨迹的增长而增加,而是和建图面积相关联。
实现 Lifelong Mapping 的思路是定期删除 PoseGraph 中冗余节点,在这过程中有两个问题需要考虑:
- 怎么判断并筛选出冗余节点
- 从PoseGraph 中删除冗余节点后,PoseGraph 需要做怎样的调整
冗余节点的选取
SLAM 的目的是构建周边环境的地图。因此,选取冗余节点的时候主要要考虑的是其对地图的影响:
- 如果去除节点之后对构建的地图不发生变化或变化很小,可以考虑为冗余节点
- 或者冗余节点的数据被其他节点覆盖,这种情况下可以直接删除节点,不会对地图的生成造成影响
了解了冗余节点的定义之后,接下来要来看一下具体怎么进行选择。在 PoseGraph 中每一个节点中都存储了一帧激光数据,以计数构图法为例:地图中每一个栅格(i)都存储被击中的次数hits(i)以及被穿过的次数misses(i)。我们用 hits(i) / (hits(i) + misses(i)) 来表示该栅格是障碍物的概率。在这个背景下,每一个节点中存储该帧激光数据穿过的栅格以及击中的栅格。
在建图中,我们使用全部节点数据构建一个完整的地图 A,得到每一个栅格被击中和被穿过的数据,如下所示:
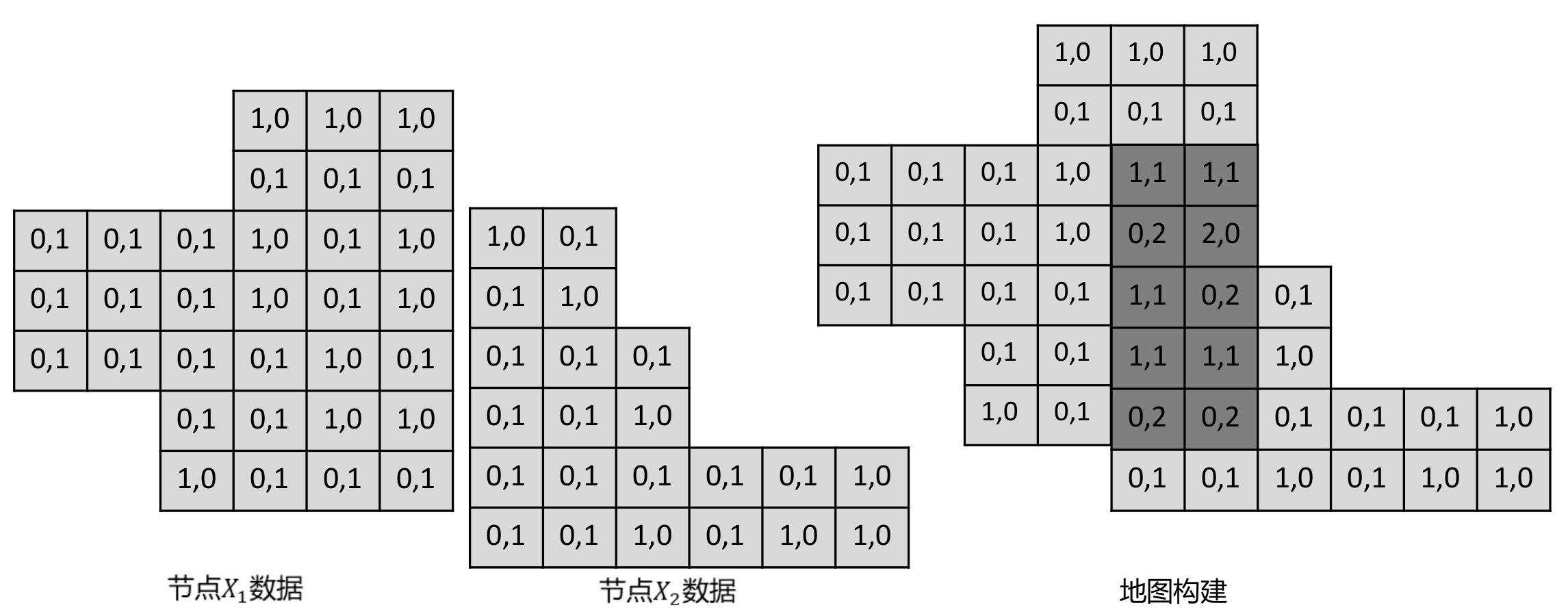
这里注意下,由于在建图过程中位姿已经知道,因此所有节点存储的都是在世界坐标系下的栅格数据。在知道了怎么用节点数据构建图之后,我们需要关注以下,对于一个节点 i,去除一个节点对地图的影响。由上可以知道,我们需要对地图做的变化时,从地图中存储该节点的数据,在该节点穿过的栅格对应的穿过次数减 1,击中的栅格对应的击中次数减 1。如下所示(黄色区域为某一帧激光数据覆盖区域):
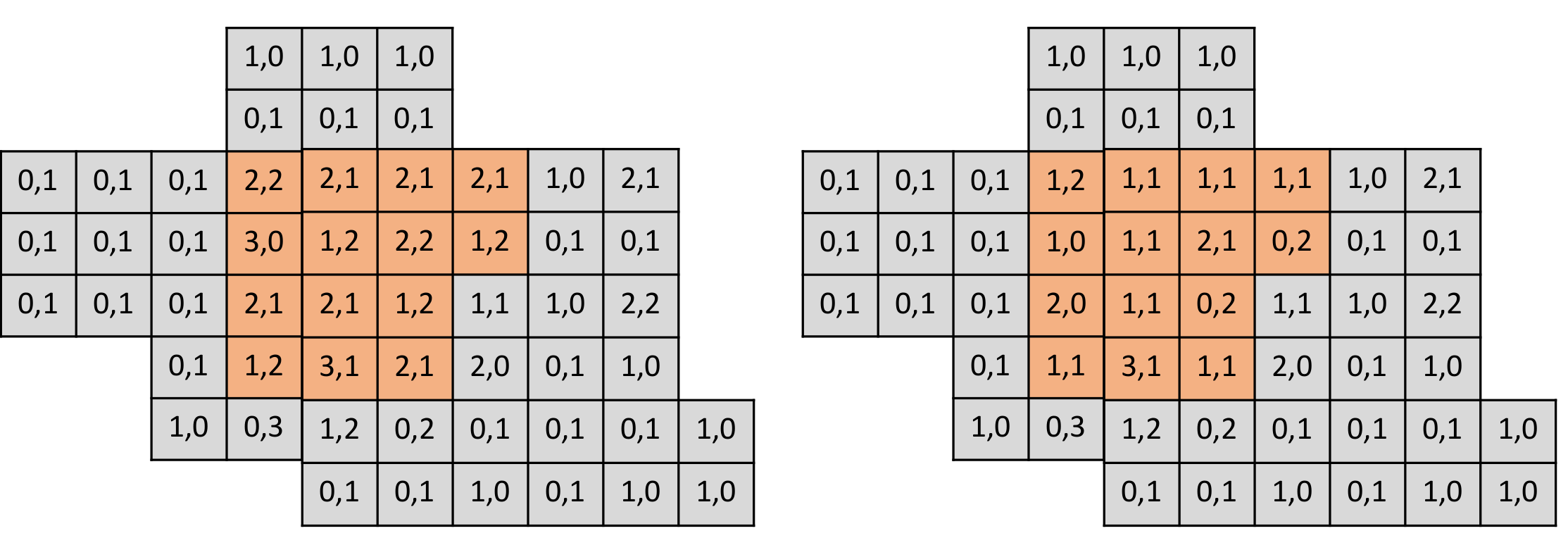
从栅格占据概率的考虑出发,我们可以定量分析去除栅格对建图的影响,可以用去除节点前后状态变化的栅格个数作为节点冗余度的指标,如下所示:
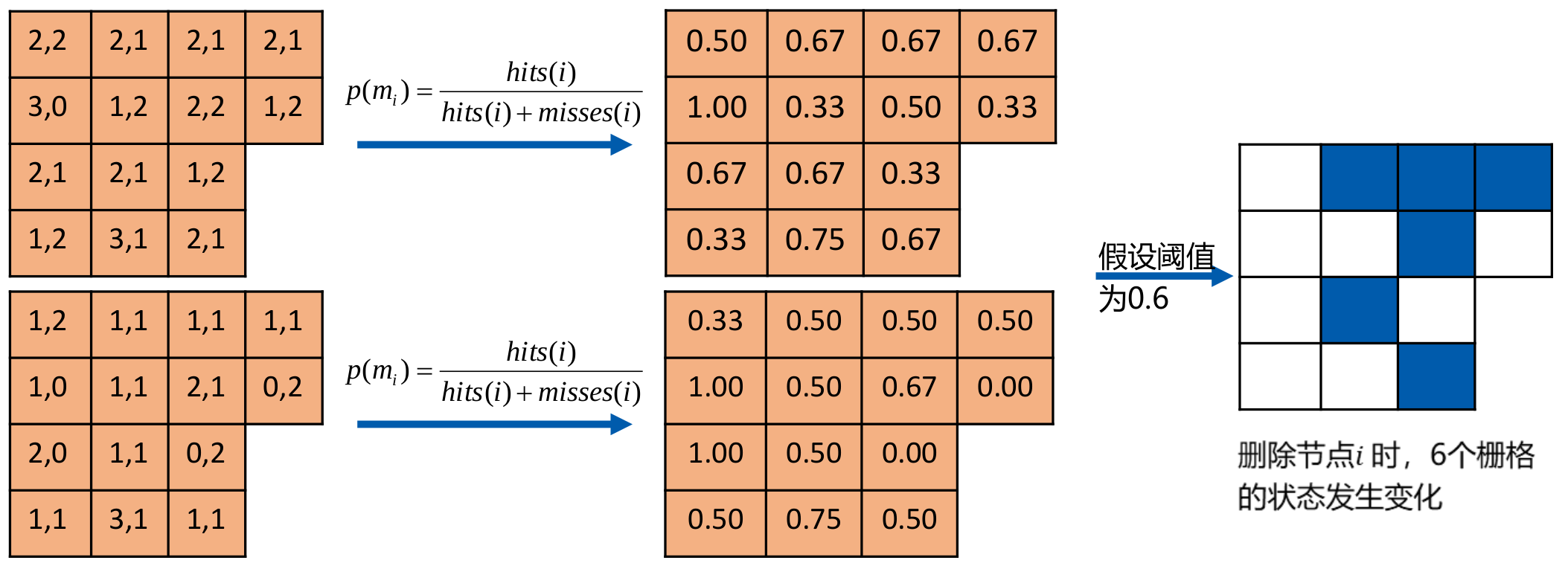
从对地图的影响来看,去除节点状态的状态变化栅格数量越少,意味着该帧数据越冗余,反之亦然。我们选择冗余节点时,以此计算每一个节点的冗余度,并选择其中最冗余的一个节点并且当其冗余度小于一定阈值时将其作为待删除节点。在确定了待删除节点之后,后面两部分我们来讨论以下如何对其进行删除
PoseGraph 的稠密近似
给定如下例子:
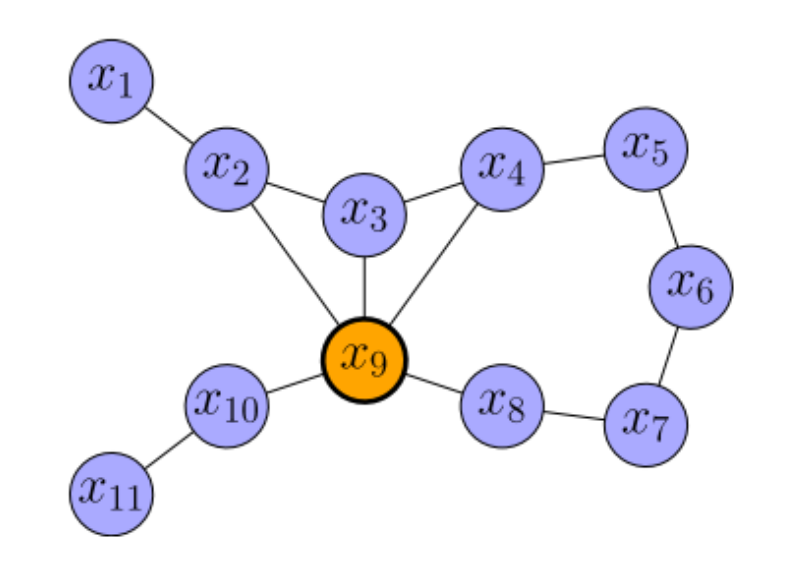
其对应的信息矩阵为:

其中橙色节点为待删除节点,我们将整个图看成一个联合概率分布:
$$
p(x_1, x_2, ..., x_9, x_10, x_11)
$$
令:
$$
\begin{aligned}
\alpha &= (x_1, x_2, ..., x_8, x_10, x_11) \\
\beta &= x
\end{aligned}
$$
则我们要做的是一个边缘化过程,即: $p(\alpha, \beta) \rightarrow p(\beta)$
根据以下结论,假设我们可以将联合概率分布表示为如下信息向量和信息矩阵表示形式:
$$
p(\alpha, \beta) = N^{-1}(
\begin{bmatrix}
\xi_\alpha \\
\xi_\beta
\end{bmatrix},
\begin{bmatrix}
\Omega_{\alpha\alpha} & \Omega_{\alpha\beta} \\
\Omega_{\beta\alpha} & \Omega_{\beta\beta}
\end{bmatrix}
)
$$
则其边缘分布也服从高斯分布,$p(a)$ 的信息箱梁和信息矩阵分别如下:
$$
\begin{aligned}
\xi &= \xi_\alpha - \Omega_{\alpha\beta}\Omega^{-1}_{\beta\beta}\xi_{\beta} \\
\Omega &= \Omega_{\alpha\alpha} - \Omega_{\alpha\beta}\Omega_{\beta\beta}^{-1}\Omega_{\beta\alpha}
\end{aligned}
$$
通过这种方法精确边缘化后的 PoseGraph 以及信息矩阵如下所示,待删除节点之间的相邻节点形成一个完整子图,使得图更加稠密。
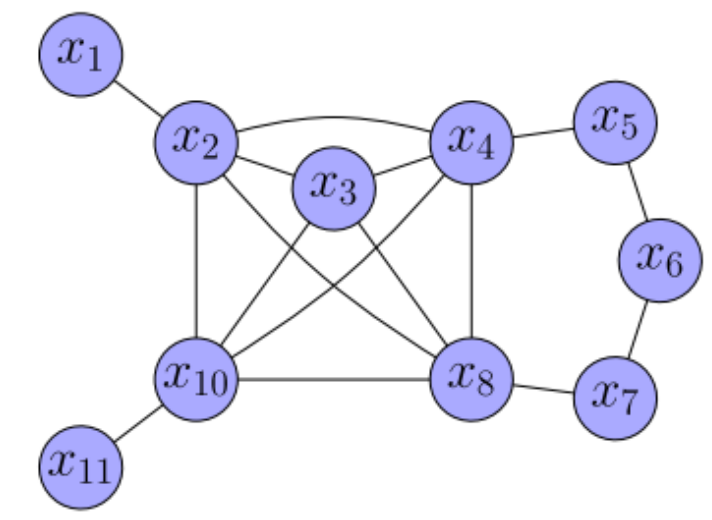
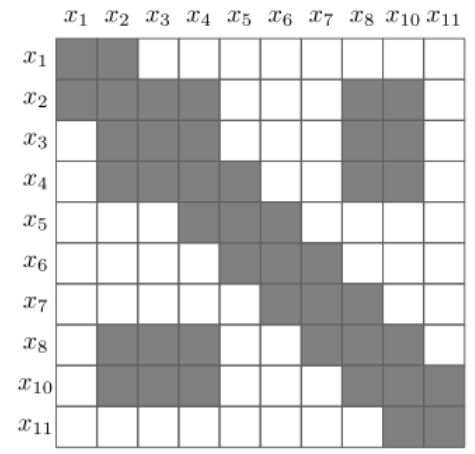
因此我们可以知道,在删除一个节点之后,我们需要在其周边构建一个完全子图,因此需要讨论一下如何计算出完全子图中新增加的边。
这里先引入第一个结论,对完全子图中,假设第 i 个节点和 第 j 个节点相对位姿服从高斯分布:
$$
\begin{aligned}
e_{ij} &\sim N(\mu_{ij}, \Sigma_{ij}) \\
\mu_{ij} &= (t_{ij}, \theta_{ij})
\end{aligned}
$$
则第 j 个节点和第 i 个节点相对位姿也服从高斯分布如下:
$$
\begin{aligned}
e_{ji} &\sim N(\mu_{ji}, \Sigma_{ji}) \\
\mu_{ji} &= -R\mu_{ij} \\
\Sigma_{ji} &= R\Sigma_{ij}R^T \\
R &= \begin{bmatrix}
R^T(\theta_{ij}) & 0 \\
0 & 1
\end{bmatrix}
\end{aligned}
$$
其中,$R(\theta)$ 表示 $\theta$ 的旋转矩阵形式
第二个结论:对完全子图中,假设第 i 个节点和 第 j 个节点以及第 j 个节点和第 k 各节点的相对位姿分别服从高斯分布:
$$
\begin{aligned}
e_{ij} &\sim N(\mu_{ij}, \Sigma_{ij}) \\
e_{jk} &\sim N(\mu_{jk}, \Sigma_{jk})
\end{aligned}
$$
则第 i 个节点和第 k 个节点的相对位姿也服从高斯分布,参数如下:
$$
\begin{aligned}
e_{ik} &\sim N(\mu_{ik}, \Sigma_{ik}) \\
\mu_{ik} &= \mu_{ij} + R\mu_{jk} \\
\Sigma_{ik} &= \Sigma_{ij} + R\Sigma_{jk}R^T \\
R &= \begin{bmatrix}
R^T(\theta_{ij}) & 0 \\
0 & 1
\end{bmatrix}
\end{aligned}
$$
上述两个结论都可以用位姿矩阵转换来证明。
从第二个结论我们可以得出在删除一个节点后如何为其相邻的两个节点构建新的边。除此之外我们还需要考虑一种情况,即这两个和冗余节点相邻的节点本身已经有边时,如何对两边进行融合,这里引入第三个结论:第 i 个节点和第 j 个节点有以下两个相对位姿关系:
$$
\begin{aligned}
e_{ij} &\sim N(\mu_{ij}, \Sigma_{ij}) \\
e_{ij}' &\sim N(\mu_{ij}', \Sigma_{ij}')
\end{aligned}
$$
其融合的相对位姿服从以下高斯分布:
$$
\begin{aligned}
e_{ij} &\sim N(\mu_{ij}, \Sigma_{ij}) \\
\mu = \Sigma(\Sigma^{-1}_{ij}\mu_{ij} + \Sigma'^{-1}_{ij}\mu_{ij}') \\
\Sigma = (\Sigma_{ij}^{-1} + \Sigma_{ij}'^{-1})^{-1}
\end{aligned}
$$
因此对上述提出的例子中,节点的去除和新边构建过程如下:
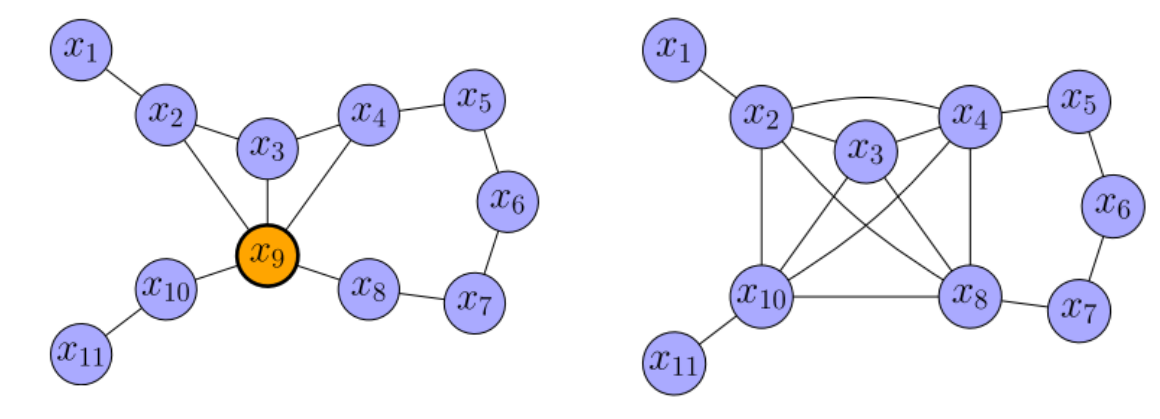
先考虑纯组合边(原先节点不存在边)
e24 = edge_composition(e29,e94)
e28 = edge_composition(e29,e98)
e210 = edge_composition(e29,e910)
e38 = edge_composition(e39,e98)
e310 = edge_composition(e39,e910)
e48 = edge_composition(e49,e98)
e410 = edge_composition(e49,e910)
接下来考虑混合边(构建边+融合边):
e23_ = edge_composition(e29,e93)
e23 = edge_combine(e23_, e23)
e34_ = edge_composition(e39, e94)
e34 = edge_combie(e34_, e34)
通过这种方法我们完全了新建完全子图中的 11 个边的计算。但是注意,我们这种构造方法在子图之间的边之间增加了一定相关性(例如 e24 和 e28 都有 e29 的信息在内),在一定程度上违反了我们用 PoseGraph 的一个假设:所有边都是独立的。因此在结果上可以效果会差一点。
PoseGraph 的稀疏近似
上面我们介绍了 PoseGraph 的稠密近似方法,在上述方法中,每删除一个节点都会在图中构建一个子图,形成很多新的边,因此随着删除节点的数的增加,图会越来越稠密也因此会一定程度上破坏 Hessian 矩阵的稀疏性质,从而无法利用矩阵稀疏性进行快速求解,会很大程度上减慢优化速度。因此这里提出另一种近似方法。
这里先介绍一种近似方法:Chow-Liu Tree 近似,过程如下所示:

途中边的厚度表示两个变量之间互信息(权重)的大小,这种近似过程等价于最大生成树,数学表示如下:
$$
\begin{aligned}
p(\tilde{\mathbf{x}}) &= p(x_k)\prod_{i=1}^{k-1}p(x_i|x_{i+1}, ..., x_k) \\
&= p(x_k)\prod_{i=1}^{k-1}p(x_i|x_{i+1}) = q(\tilde{\mathbf{x}})
\end{aligned}
$$
在上面的近似过程中,我们需要求边的互信息大小,计算方法如下:
$$
I(x_i;x_j) = \frac{1}{2}\log_2{(\frac{|\tilde{\Sigma_{ii}}|}{|\tilde{\Sigma_{ii}} - \tilde{\Sigma_{ij}}\tilde{\Sigma_{jj}^{-1}}\tilde{\Sigma_{ji}}|})}
$$
其中,$x$ 表示节点,$\Sigma$ 表示完全子图中的协方差矩阵。这里可以得出近似过程:近似之后节点的均值就是目前各个节点的位姿,协方差矩阵通过构造全图的信息矩阵,然后进行边缘化得到完全子图的信息矩阵,最后求逆得到完全子图的协方差矩阵即可。
通过稀疏近似之后的 PoseGraph 图以及 Hessian 矩阵如下所示:
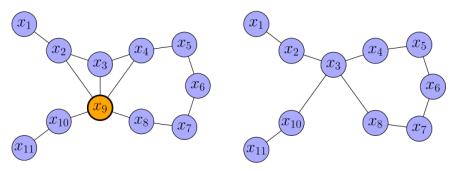

可以发现,这种近似方法不会使得图过度稠密。
稀疏近似的流程如下:
- 找到待删除节点 i
- 对 PoseGraph 进行边缘化,得到整体分布 A
- 从整体分布 A 进行边缘化,得到完全子图的分布 B
- 计算子图节点之间的互信息,用起作为边的权重,构造图
- 利用最大生成树决定需要保留的边