基于相关性的方法
这篇博文整理了激光 slam 中点云配准的另一种方法——基于相关性的方法。相较于 ICP 方法,这种匹配方法不需要找到两个点云之间的对应点的匹配的关系,而是将待匹配的点和上一帧中进行相关性的比较。通过将待匹配的点转换至上一帧点云中,利用点云周围的信息(不是具体的某个点)得到一个得分(概率),通过最大得分来获得较优的位姿估计。
NDT (Normal Distribution Transform) 方法
基本思想
NDT 方法的基本思想是将空间划分成一个个 cell,这里的 cell 的概念要和栅格 grid 区分一下,通常单个栅格会取很小,其只代表了一个值。相对而言,cell 更像是一个小区域。有了各个 cell 之后为每一个 cell 定义一个高斯分布用来替代势场,因此整个空间里面就形成了一个分段连续的势场(在各自的 cell 里面连续)。
将待匹配的点先通过估计的位姿转化到上一帧的坐标系中,再找到该点所处的 cell,然后去计算在 cell 中的高斯分布下,该点出现情况的概率。即计算该点和上一帧中在那个 cell 中的其他点符合同一个高斯分布的概率。这里之所以将 cell 中的点视为符合高斯分布,我的理解是我们将 cell 的空间尺寸控制的比较小,将其内的点视为对一个特征的不同观测,而由于观测中的误差引入,因此观测值会呈现出一个随机分布。而由于大部分误差服从高斯分布,因此用高斯分布去拟合该区域的点是比较合理的。
数学描述
这里以 2D 情况为例,假设:
$T = (t_x, t_y, t_\theta)$ 表示需要求解的值
$x_i = (x, y)^T$ 表示待匹配的激光点坐标
$$
\begin{aligned}
T(x_i) = \begin{bmatrix}
\cos{\theta} & -\sin{\theta} \\
\sin{\theta} & \cos{\theta}
\end{bmatrix}
\begin{bmatrix}
x_i \\ y_i
\end{bmatrix} +
\begin{bmatrix}
t_x \\ t_y
\end{bmatrix}
\end{aligned}
$$
$\mu_i$, $\Sigma_i$ 分别表示 $x_i$ 对应点所在 cell 的高斯分布的均值和方差,使用上一帧点云在该 cell 中的所有点计算:
$$
\begin{aligned}
\mu_i &= \frac{1}{n_i}\sum_{j\in\text{cell}_i}x_j\\
\Sigma &= \frac{1}{n_i}\sum_{j\in\text{cell}_i}((x_j - \mu_i)(x_j - \mu_j)^T)
\end{aligned}
$$
将待匹配点使用估计的位姿转换到上一帧中,计算其对于该高斯分布的概率衡量标准:
$$
\begin{aligned}
x_i' &= T(x_i)\\
p(x_i') &= -\exp{(-\frac{(x_i' - \mu_i)^T\Sigma_i^{-1}(x_i' - \mu_i)}{2})}
\end{aligned}
$$
由于这里的标准是概率,因此所有的点累积起来的概率应该相乘,有:
$$
\begin{aligned}
p(T) &= \prod_ip(T(x_i))\\
&= \prod_i\left(\exp{(-\frac{(x_i' - \mu_i)^T\Sigma_i^{-1}(x_i' - \mu_i)}{2})}\right)
\end{aligned}
$$
则对应的目标函数如下所示:
$$
\begin{aligned}
T^* &= \arg\max_{T}p(T)\\
&= \arg\max_{T}\left(\prod_i\left(\exp{(-\frac{(x_i' - \mu_i)^T\Sigma_i^{-1}(x_i' - \mu_i)}{2})}\right)\right)\\
&= \arg\max_{T}\left(\prod_i\left(\exp{(-\frac{(x_i' - \mu_i)^T\Sigma_i^{-1}(x_i' - \mu_i)}{2})}\right)\right)\\
&= \arg\max_{T}\left(\sum_i\left((-\frac{(x_i' - \mu_i)^T\Sigma_i^{-1}(x_i' - \mu_i)}{2})\right)\right)\\
&= \arg\min_{T}\left(\sum_i\left((x_i' - \mu_i)^T\Sigma_i^{-1}(x_i' - \mu_i)\right)\right)\\
&= \arg\min_{T}\left(\sum_i||T(x_i) - \mu_i||_{\Sigma_i^{-1}}^2\right)\\
\end{aligned}
$$
因此,我们将这个问题转化为一个非线性最小二乘问题,关于非线性最小二乘问题的求解可以参考:最小二乘问题和非线性优化。这里,由于残差的结构比较简单,对于二维的情况我们可以直接求二阶导 Hessian 矩阵使用牛顿法求解,如果在三维的情况,求 Hessian 矩阵比较复杂,则可以只求一阶导 Jacobian 矩阵,用 $J^T\Sigma^{-1}J$ 来近似 Hessian 矩阵,即使用高斯牛顿法进行求解。
算法流程
总结以下, NDT 方法的算法流程分三步:
- 对环境进行 cell 的划分,为每一个 cell 构造一个高斯分布
- 根据初始解把当前帧的激光点转换到参考帧上,并确定属于哪个 cell
- 用牛顿法/高斯牛顿法进行迭代求解
NDT 改进方向
- 对点云进行预处理(在 3D 情况下尤其需要进行下采样)
- 取 cell 的策略:有以下几种思路:
- 固定尺寸进行划分
- 八叉树划分
- 通过聚类后再取栅格
- 增加鲁棒性
- 上面提到我们将空间划分成不同 cell,每个 cell 中维护一个高斯分布,那这样不可避免地在相邻栅格地交界处,分布会出现不连续性,因此一个思路可以是在每两个栅格之间通过插值计算出交界处附近的分布
高斯牛顿优化方法
(待更新。)
基本原则 & 数学描述
HectorSLAN 使用的是这种方法。根据基于优化方法,只要给定一个目标函数,我们可以把激光帧间的匹配问题转换为求解目标函数的极值问题(通常是求最小值):
$$
E(T) = \arg \min_{T} \sum{[1 - M(S_{i}(T))]^2}
$$
其中, T 表示当前机器人的位姿矩阵 $T = T(T_x, T_y, T_\theta)$, $S_{i}(T)$ 表示将激光点 i 通过 T 转换后的坐标(可以认为是地图坐标),$M(x)$ 表示得到当前坐标下的地图的占用概率,这个值可以认为是转换后的坐标离真实值的相差程度,离真实值越近值越大,具体的计算方法是通过查表求得该点的值,注意这里并不是找某对点的匹配程度,而是比较两个地图。
目标函数求解
如上所示,我们的目标函数为:
$$
E(T) = \arg \min_{T} \sum{[1 - M(S_{i}(T))]^2}
$$
其中,假设 $p_i = (p_{ix}, p_{iy})$ 表示第 $i$ 个激光点的坐标,则有:
$$
S_{i}(T) = \begin{bmatrix}\cos{T_\theta} & -\sin{T_\theta} & T_x \\
\sin{T_\theta} & \cos{T_\theta} & T_y\\
0 & 0 & 1\end{bmatrix}\begin{bmatrix}p_{ix}\\p_{iy}\\1\end{bmatrix}
$$
因为 $M(S_{i}(T))$ 为非线性函数,求极值需要对其进行一阶泰勒展开,则有:
$$
\begin{aligned}
& E(T) = \arg \min_{T} \sum{[1 - M(S_{i}(T))]^2} \\
\rightarrow & E(T+\Delta T) = \arg \min_{T} \sum{[1 - M(S_{i}(T)) - \nabla M(S_{i}(T))\frac{\partial{S_{i}(T)}}{\partial{T}}\Delta{T}]^2}
\end{aligned}
$$
对于上述线性方程,求极值可以通过求其对 $\Delta{T}$ 的导数,并使之为0,前两项和变量无关,直接去掉,
令:
$$
f(x) = 1 - M(S_{i}(T)) -\nabla M(S_{i}(T))\frac{\partial{S_{i}(T)}}{\partial{T}}\Delta{T}
$$
则有:
$$
\begin{aligned}
\frac{\partial{(\sum{f(x)})^2}}{\partial{x}} = 2\sum{f(x)\frac{\partial{f(x)}}{\partial{x}} }&=0\\
\sum{f(x)\frac{\partial{f(x)}}{\partial{x}}} &=0
\end{aligned}
$$
即:
$$
\sum{[\nabla M(S_{i}(T))\frac{\partial{S_{i}(T)}}{\partial{T}}]^{T}[ 1 - M(S_{i}(T)) -\nabla M(S_{i}(T))\frac{\partial{S_{i}(T)}}{\partial{T}}\Delta{T}]} = 0
$$
我们需要求解上式得到 $\Delta{T}$,然后令 $T = T + \Delta{T}$,进行迭代即可。展开上式得:
$$
\begin{aligned}
&\sum{[\nabla{M(S_{i}(T))}\frac{\partial{S_{i}(T)}}{\partial{T}}]^T[ 1 - M(S_{i}(T)) -\nabla M(S_{i}(T))\frac{\partial{S_{i}(T)}}{\partial{T}}\Delta{T}]} = 0 \\
&\sum{[\nabla{M(S_{i}(T))}\frac{\partial{S_{i}(T)}}{\partial{T}}]^T[ 1 - M(S_{i}(T))]} =\\
&\qquad \qquad\qquad \sum{[\nabla{M(S_{i}(T))}\frac{\partial{S_{i}(T)}}{\partial{T}}]^T[\nabla M(S_{i}(T))\frac{\partial{S_{i}(T)}}{\partial{T}}]\Delta{T}}
\end{aligned}
$$
令:
$$
\begin{aligned}
b &= \sum{[\nabla M(S_{i}(T))\frac{\partial{S_i(T)}}{\partial{T}}]^T[ 1 - M(S_i(T))]} \\
J &= \nabla{M(S_i(T))}\frac{\partial{S_i(T)}}{\partial{T}} \\
H &= \sum{J^{T}J}
\end{aligned}
$$
则上式可以简化为:$H\Delta{T} = b$,两边同乘$H^{-1}$,则有:
$$
\Delta{T} = H^{-1}b
$$
其中,
$$
\begin{aligned}
S_{i}(T) &= \begin{bmatrix}
\cos{T_\theta} & -\sin{T_\theta} & T_x \\
\sin{T_\theta} & \cos{T_\theta} & T_y\\
0 & 0 & 1\end{bmatrix}\begin{bmatrix}p_{ix}\\p_{iy}\\1
\end{bmatrix} \\
&= \begin{bmatrix}
\cos{T_\theta}p_{ix} - \sin{T_\theta}p_{iy} + T_x \\
\sin{T_\theta}p_{ix} + \cos{T_\theta}p_{iy} + T_y \\
1
\end{bmatrix}
\end{aligned}
$$
最后一项常数可以不管(求导等于0, 最后补一行 0即可),对其求导有:
$$
\frac{\partial{S_{i}(T)}}{\partial{T}} = \begin{bmatrix}
1 & 0 & -\sin{T_\theta} p_{ix} - \cos{T_\theta}p_{iy} \\
0 & 1 & \cos{T_\theta} p_{ix} - \sin{T_\theta}p_{iy}
\end{bmatrix}
$$
至此,在上式($\Delta{T}$ 求解)中,除了 $\nabla{M(S_{i}(T))}$ 以外,其他变量都是已知,下面进行 $\nabla{M(S_{i}(T))}$ 求解。我们知道 $S_{i}(T)$ 表示地图坐标点, $M(S_{i}(T))$ 表示该点的地图势场值(离点云真实值越近值越大),在计算势场值的时候,我们通常是把地图离散化变成一个二维(三维)的矩阵用来表示地图各点的势场值,这个值通过查表得出,$\nabla{M(S_{i}(T))}$ 表示地图势场对该点的导数,对于 $\nabla{M(S_{i}(T))}$ 和部分 $M(S_{i}(T))$ (不在矩阵离散点内的),需要对地图进行插值。
地图双线性插值
如下图所示,假设我们要求 $P_m$ 的势场值以及对应导数的值,我们需要对离散地图进行差值,这里我们使用拉格朗日插值法分别对 X, Y 两个方向进行插值,是一维线性插值的推广
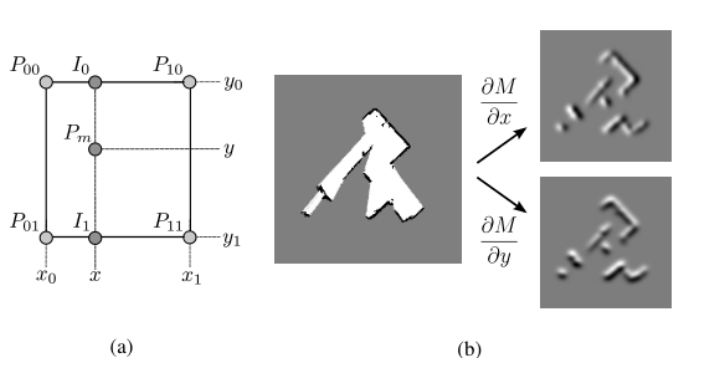
朗格朗日插值方法 - 一维线性插值
拉格朗日插值的方法的主要特点是将插值多项式表示成基函数的线性组合:
$$
L_n(x) = \sum_{i = 0}^{n}{(l_i(x)y_i)}
$$
其中,基函数 $l_i(x)$ 满足以下条件:
$$
l_i(x_k) = \left\{ \begin{aligned}
1 & & k = i \\
0 & & k \neq i
\end{aligned}\right.
$$
朗格朗日插值方法 - 基函数构造
通过上面式子,我们可以将基函数构造成:
$$
l_i(x) = c(x - x_0)(x - x_1)...(x - x_{i-1})(x-x_{i})...(x-x_n)
$$
显然这个式子满足上述条件,因为有$l_i(x_i) = 1$,有:
$$
c = \frac{1}{(x - x_0)...(x-x_{i})...(x-x_n)}
$$
则:
$$
l_i(x) = \prod_{k = 0, k\neq i}^{n}\frac{x - x_k}{x_i - x_k}
$$
朗格朗日插值方法 - 双线性插值
设平面中有四个点及其势场值:
$$
\begin{aligned}
Z_1 = M(P_{00}) &= f(x_0, y_0) \\
Z_2 = M(P_{10}) &= f(x_1, y_0) \\
Z_3 = M(P_{11}) &= f(x_1, y_1) \\
Z_4 = M(P_{01}) &= f(x_0, y_1) \\
\end{aligned}
$$
我们定义一个新的坐标:
$$
\begin{aligned}
u &= \frac{x - x_0}{x_1 - x_0} \\
v &= \frac{y - y_0}{y_1 - y_0}
\end{aligned}
$$
则在这个坐标系下有:
$$
\begin{aligned}
(x_0, y_0) &= (0, 0) \\
(x_1, y_0) &= (1, 0) \\
(x_1, y_1) &= (1, 1) \\
(x_0, y_1) &= (0, 1) \\
\end{aligned}
$$
根据上一部分的方法构造基函数:
$$
\begin{aligned}
l_1(u, v) &= (1-u)(1-v) \\
l_2(u, v) &= u(1 -v) \\
l_3(u, v) &= uv \\
l_4(u, v) &= (1-u)v
\end{aligned}
$$
通过上一部分,插值函数为:
$$
L_4(u, v) = Z_1l_1(u, v) + Z_2l_2(u, v) + Z_3l_3(u, v) + Z_4l_4(u, v)
$$
地图插值
将上述插值方式转换为原来的坐标系有:
$$
\begin{aligned}
L(x, y) &= \frac{y - y_0}{y_1 - y_0}(\frac{x - x_0}{x_1 - x_0}(P_{11}) + \frac{x_1 - x}{x_1 - x_0}(P_{01})) \\
&+ \frac{y_1 - y}{y_1 - y_0}(\frac{x - x_0}{x_1 - x_0}(P_{10}) + \frac{x_1 - x}{x_1 - x_0}(P_{00}))
\end{aligned}
$$
其对 x 和 y 的偏导数分别为:
$$
\begin{aligned}
\frac{\partial{L(x, y)}}{\partial{x}} &= \frac{y - y_0}{y_1 - y_0}(M(P_{11}) - M(P_{01})) + \frac{y_1 - y}{y_1 - y_0}(M(P_{10}) - M(P_{00})) \\
\frac{\partial{L(x, y)}}{\partial{y}} &= \frac{x - x_0}{x_1 - x_0}(M(P_{11}) - M(P_{10})) + \frac{x_1 - x}{x_1 - x_0}(M(P_{01}) - M(P_{00}))
\end{aligned}
$$
至此,我们可以求得 $\nabla{M(S_{i}(T))}$ 和 $M(S_{i}(T))$ 的值,进而求得 $\Delta{T}$,并进行迭代计算求得目标函数最小值。
相关匹配方法及分枝定界加速 (CSM)
(待更新。)
相关方法(Correlation-based Method)——基本思想
相关方法的基本思想是通过在一个范围内通过枚举所有位姿的可能性,从中选择一个最好的作为结果。这么做的原因主要是因为考虑到我们面对的是一个高度非凸问题,可能会有非常多局部极值,所以迭代方法对初值非常敏感,所以采用暴力匹配的方法可以避免出现初值影响,但是这么做的问题是计算量太大,所以通常需要通过加速策略来降低计算量。同时这个方法还有一个好处是可以计算位姿匹配的方差。
相关方法——算法流程

- 如上图所示,首先我们需要对地图通过高斯模糊来构造似然场
- 在一个指定的搜索空间(比如 1m×1m,30°范围内)来进行搜索,这里可以有不同搜索的方法,后面会详细描述;对搜索得到的每一个位姿进行得分计算(匹配程度)
- 根据上一步得到位姿得分,计算本次位姿匹配的方差
相关方法——位姿搜索
常用的搜索方式主要包括以下几种:
- 暴力搜索:通过多层循环(对
$(x, y, \theta)$而言是三层)枚举每一个位姿,分别计算每一个位姿的得分,计算量巨大。因为激光雷达数据在每一个位姿都要重新投影,投影需要计算 sin 和 cos 函数(循环顺序是:$x\rightarrow y\rightarrow \theta$); - 预先投影搜索:把暴力搜索中的三层循环
$(x, y, \theta)$交换一下顺序,最外层对$\theta$进行搜索,这样内层$x, y$的投影不需要单独计算 sin 和 cos 值,需要计算 sin 和 cos 函数的位姿数从$n_xn_yn_\theta$降为$n_\theta$。能极大的加速算法的运行速度; - 多分辨率搜索:
- 构造粗分辨率 25cm 和细分辨率 2.5cm 两个似然场
- 首先在粗分辨率似然场上进行搜索,获取最优位姿
- 把粗分辨率最优位姿对应的栅格进行细分辨率划分,然后再进行细分辨率搜索,再次得到最优位姿。
- 要求:粗分辨率地图的栅格的似然值为对应的细分辨率地图对应空间的所有栅格的上界
分枝定界算法——基本思想
分枝定界算法是一种常用的树形搜索剪枝算法,主要用来求解整数规划问题。可以将最优解问题转换为树形搜索问 题,根节点表示整个解空间,叶子节点表示最优解,中间的节点表示解空间的某一部分子空间。
算法主要分为两部分:
- 分枝:跟节点表示整个解空间,深度为 1 的节点表示解空间的 n 个子空间之一(分辨率是根节点的 1 / n),以此类推。将解空间层层划分直至到真实解(分辨率达到所需要求)即叶节点。
- 定界:要实现通过剪枝来进行加速(dfs 搜索),对于某个子树而言,必须保证该子树根节点的值是该子树所有节点的值的上界(如果是求解最小值问题就是下界);这样在搜索过程过程中只需要维护一个当前最优值,当遇到某个节点的值低于该值,我们就不需要对以该节点为根节点的子树进行搜索,从而进行加速。
分支定界算法—— score 函数定义
从上面可知,分枝定界算法当中一个核心问题就是怎么定义一个 score 函数使得其能够上面提到的要求:对任意子树,根节点的值是该子树所有节点的值的上界
首先,搜索树中的节点表示一个正方形的搜索范围 $(c_x, c_y, c_\theta, c_h)$, $c_h$ 为高度。根节点最高,即:
$$
\overline{\overline{W}}_c = (\{
(j_x, j_u)\in \mathbb{Z}^2:
\begin{aligned}
c_x \leq j_x \leq c_x + 2^{c_h} \\
c_y \leq j_y \leq c_y + 2^{c_h}
\end{aligned}
\} \times {c_\theta})
$$
分枝:对于节点 $(c_x, c_y, c_\theta, c_h)$,分枝为 4 个子节点,分别为:
$$
C_c = ((\{c_x, c_x + 2^{c_h-1}\}\times \{c_y, c_y + 2^{c_h-1}\}\times c_\theta) \cap \overline{W}) \times \{c_h - 1\}
$$
定界:score 函数定义及证明如下:
$$
\begin{aligned}
score(c) &= \sum_{k = 1}^{k}\max_{j \in \overline{\overline{W}}_c} M_{nearest}(T_{\zeta_j}, h_k) \\
&\geq \sum_{k = 1}^{K}\max_{j \in \overline{W}_c} M_{nearest}(T_{\zeta_j}, h_k) \\
&\geq \max_{j \in \overline{W}_c}\sum_{k = 1}^{K} M_{nearest}(T_{\zeta_j}, h_k)
\end{aligned}
$$
如上述,第一行和第二行表示取当前层空间和下一层空间所有解的每一个激光束遍历所有位置取最大匹配值(注意:对每一个激光束取得分最大值的位姿可能会不同),显然对第一个式子大于等于第二个,因为搜索范围更大;第三行则是对下一层所有解空间挑出一个位姿使得所有激光束的得分之和最大,第二个式子的结果大于等于第三个,因为对单个位姿而言并不一定能保证所有激光束的匹配结果都是最大。得分函数是预先计算的,在进行计算的时候可以直接取,因此这是一种空间换时间的做法。
分枝定界算法——算法流程
以下是两种分枝定界算法的算法流程伪代码
