简介
原论文见:RoadMap: A Light-Weight Semantic Map for Visual Localization towards Autonomous Driving,作者秦通大佬在知乎也写了中文讲解,见:不用高精地图行不行?RoadMap:自动驾驶轻量化视觉众包地图。大佬的文章大致概括了论文的整体思路,这篇博客主要是对论文中自己比较感兴趣且和工作较为相关的部分进行阅读和记录。
目前,采用 RTK-GPS 配合激光雷达匹配定位是大多数 Robot-taxi 的定位方案,然而激光雷达和高精地图使得方案的整体成本较高,给量产带来一定问题。此外,激光雷达点云需要占有大量存储空间,不适合大范围地区推广,且高精地图本身需要的人力维护成本也较高。在这篇论文中,作者提出了一种轻量化的定位方案,主要依赖相机和紧凑的视觉语义地图。语义地图中包含:车道线、人行横道、地面标志等语义特征;可以由其他配备多种激光雷达的汽车以众包的方式生成。在只有相机的普通车辆可以依赖图片中检测到的语义特征进行定位。
文献综述
略。
系统总览
整体系统流程图如下所示:
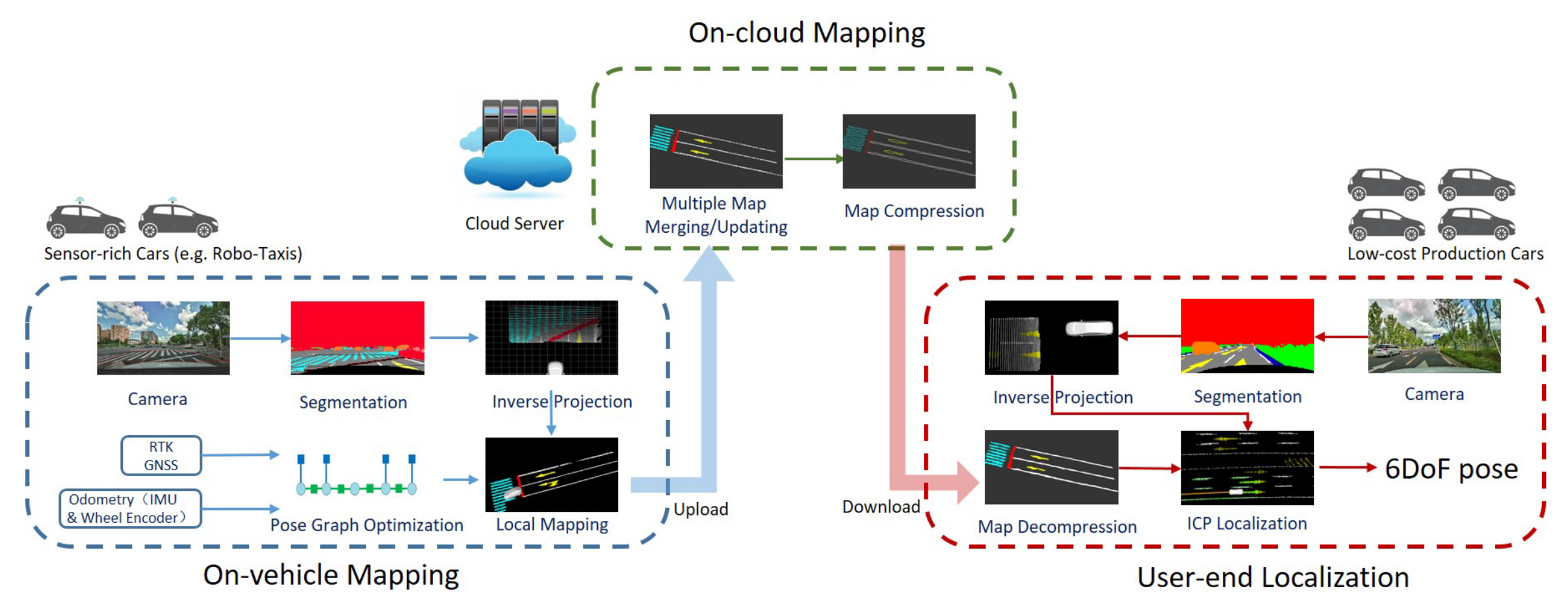
系统可以分为三部分
- 汽车本地建图:汽车使用前视照相机、RTK-GPS、IMU 和轮式编码器等传感器进行融合建图。其中 RTK-IMU 可以用来进行车辆位姿估计,相机图片可以用来提取语义特征,将提取到的语义特征投影至世界坐标系可以建立局部的语义地图。
- 云端建图:汽车在本地建立的局部语义地图会上传至云端,云端服务器收集多个汽车的局部地图,通过拼接形成全局地图,然后对全局地图采用轮廓提取的方法进行压缩
- 用户端定位:用户可以实时获取最新的全局地图,只需要有低成本的相机、GPS、IMU 和编码器即可通过 GPS 和 IMU 进行粗定位,再结合语义信息匹配获取较为准确的位置估计
车端建图
图片语义分割
采用常用的 CNN 可以对相机采集的图片进行语义分割。这篇论文里面作者使用了车道线、地面、停止线、路面标志、过往车辆、自行车和行人的信息。以下图片展示了一个图片的识别结果:
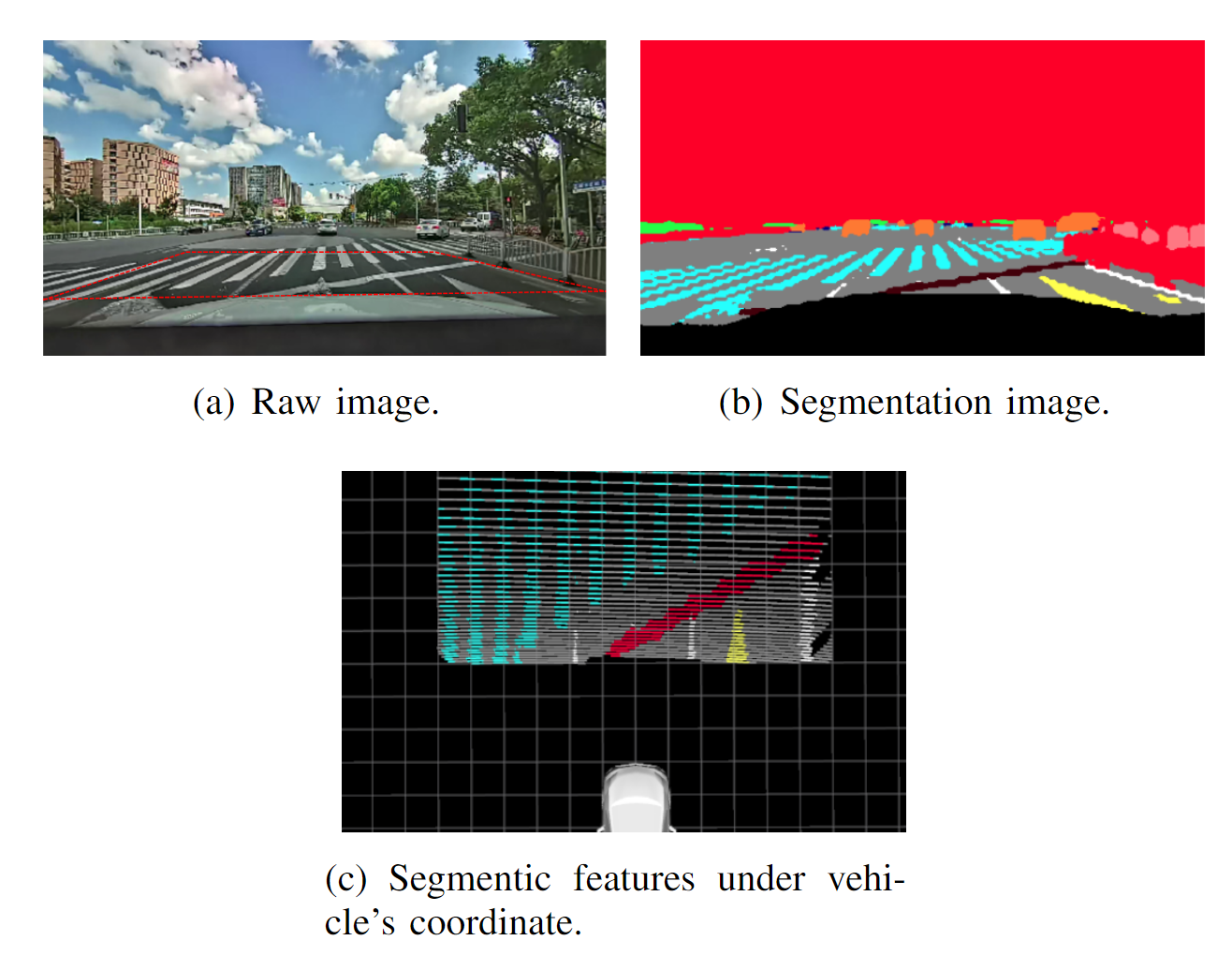
逆透视变换
通过语义分割之后,需要将带有语义信息的像素从图片坐标系转换至汽车坐标系。相机的内参以及到车辆中心的外参已经经过离线标定,考虑到距离越远透视带来的误差更大。作者在图片选定一个区域(ROI),大小为汽车前方 12m x 8m 的区域,只对该区域内的像素进行变换(可以参考上图)。假设地面是一个平面,每个像素 $[u, v]$可以通过下式投影至汽车坐标系下的地面平面 $z = 0$ 下:
$$
\frac{1}{\lambda}
\begin{bmatrix}
x^v\\
y^v\\
1
\end{bmatrix} =
\begin{bmatrix}
\boldsymbol{R}_c & \boldsymbol{t}_c
\end{bmatrix}^{-1}_{\text{col}:1,2,4}
\pi^{-1}_c
(\begin{bmatrix}
u\\v\\1
\end{bmatrix})
$$
其中,$\pi_c()$ 为相机的畸变和投影模型,$\pi^{-1}_c$ 将像素坐标转换为空间坐标。$[\boldsymbol{R}_c \quad \boldsymbol{t}]$ 为汽车对相机的外参矩阵,由于我们知道地面对应的高度为 $z = 0$,因此可以计算出逆深度系数 $\lambda$。上图展示逆变换之后的结果。
位姿图优化
虽然 RTK-GNSS 可以提供厘米级的定位精度,但是在有遮挡物时会获取不到信号,因此可以结合 IMU 在 GNSS 被遮挡时作为里程计,但是里程计本身存在累计误差,因此需要位姿结合图优化来对里程计轨迹进行优化。位姿图如下所示,优化变量(节点)为汽车状态 $\boldsymbol{s}$,包含位置 $\boldsymbol{p}$ 和姿态四元数 $\boldsymbol{q}$ ($\boldsymbol{R}(\boldsymbol{q})$ 为旋转矩阵)。位姿图中边有两类:GNSS 对位置的绝对测量,IMU 对前后两时刻位姿的相对测量。图优化过程可以由下方式定义:
$$
\min_{\boldsymbol{s}_0, ..., \boldsymbol{s}_n}\left\{\sum_{i \in[1, n]}||\boldsymbol{r}_o(\boldsymbol{s}_{i-1}, \boldsymbol{s}_i, \hat{\boldsymbol{m}}^o_{i-1, i})||^2_{\boldsymbol{\sigma}} + \sum_{i\in\mathcal{G}}||\boldsymbol{r}_g(\boldsymbol{s}_i, \hat{\boldsymbol{m}}^g_i)||^2_{\boldsymbol{\sigma}}\right\}
$$
其中,$\boldsymbol{r}_o, \boldsymbol{r}_g$ 分别为里程计和 GNSS 的残差因子。其中,$\hat{\boldsymbol{m}}^o_{i-1, i}$ 和 $\hat{\boldsymbol{m}}^g_i$ 分别为里程计和 GNSS 的测量值。分别提供前后两帧的位置和姿态变化约素 $\delta\hat{\boldsymbol{p}}_{i-1,i}$,$\delta\hat{\boldsymbol{q}}_{i-1,i}$ 以及对应帧的全局位置约束 $\hat{\boldsymbol{p}}_i$,两因子的计算方法如下图所示:
$$
\begin{aligned}
\boldsymbol{r}_o(\boldsymbol{s}_{i-1}, \boldsymbol{s}_i, \hat{\boldsymbol{m}}^o_{i-1, i}) &=
\begin{bmatrix}
\boldsymbol{R}(\boldsymbol{q}_{i-1})^{-1}(\boldsymbol{p_i}-\boldsymbol{p}_{i-1}) - \delta\hat{\boldsymbol{p}}_{i-1,i}\\
[\boldsymbol{q}_i^{-1}\boldsymbol{q}_{i-1}\delta\hat{\boldsymbol{q}}_{i-1,i}]_{xyz}
\end{bmatrix}\\
\boldsymbol{r}_g(\boldsymbol{s}_i, \hat{\boldsymbol{m}}_i^g) &= \boldsymbol{p}_i - \hat{\boldsymbol{m}}^g_i
\end{aligned}
$$
局部建图
通过位姿图优化可以获得准确的汽车全局坐标,接下来讲汽车坐标系下的语义特征像素转换至全局坐标系下:
$$
\begin{bmatrix}
x^w\\y^w\\z^w
\end{bmatrix} =\boldsymbol{R}(\boldsymbol{q}_i)
\begin{bmatrix}
x^v \\ y^v \\ 0
\end{bmatrix} + \boldsymbol{p}_i
$$
每个特征可能会被多次观测,但是考虑到语义分割误差,某一些特征的识别结果可能会不一致,作者利用各个观测之间的统计数据来进行噪声处理,他们将地图划分成为 0.1m x 0.1m x 0.1m 的小栅格,每个栅格包含位置、语义标签、和每种语义标签的数量。语义标签包括:车道线、停止线、地面标志和人行横道。每种语义标签的得分初始化为 0,每当一个新的语义标签点插入栅格中时,对应标签的数量增加一,数量最多的语义标签作为该栅格的语义标签。通过这种方法,语义地图会相对准确且对噪声具有鲁棒性。以下为一个全局地图例子:

云端建图
地图合并和更新
云端服务器接收所有车辆建立的局部地图,考虑到宽带的原因,只有被占据的栅格会被作为信息传输。云端服务器保存的语义地图同样分辨率为 0.1x0.1x0.1m。按照栅格位置对全局地图进行更新(包含语义信息和各自得分),同样每个栅格中的最高得分的语义标签作为该栅格更新后的语义标签,详细过程参考下图。

地图压缩
考虑到普通车辆的带宽不足以传输大规模的栅格数据,因此需要对云端服务器的地图进行压缩,由于语义特征通常可以用轮廓来表示,作者采用了轮廓提取的方式对地图进行压缩,首先获取语义地图的俯视图,然后对每个语义特征进行轮廓提取。轮廓点被存储并发下普通车辆。上图 6 中展示了该过程。
用户端定位
地图解压缩
同样,如图 6 所示,用户车辆接收到压缩地图之后对每个语义标签内的轮廓进行填充,然后从图片平面反投影至世界坐标系。
ICP 定位
和建图过程类似,首先从相机采集的图片中进行语义分割,获取语义特征点集,通过将这些语义特征点集和语义地图进行 ICP 匹配可以获得汽车位姿,如下所示:
$$
\boldsymbol{q}^*, \boldsymbol{p}^* = \arg\min_{\boldsymbol{q}, \boldsymbol{p}}||\boldsymbol{R}(\boldsymbol{q})
\begin{bmatrix}
x^v_k\\
y^v_k\\
0
\end{bmatrix} + \boldsymbol{p} -
\begin{bmatrix}
x^w_k\\
y^w_k\\
z^w_k
\end{bmatrix}||^2
$$
在实践时,作者采用了 EKF 框架来对里程计的结果和视觉定位进行融合,提高系统鲁棒性和保证轨迹的平滑。
实验
地图生成
作者团队在上海浦东进行了一系列测试,通过和 Google Map 对齐来判断地图精度。道路网络全长 22KM,原始语义地图的大小为 16 MB,压缩后的地图大小为 0.786 MB,可以看出地图相当轻量。地图的更细过程可以参考上图。
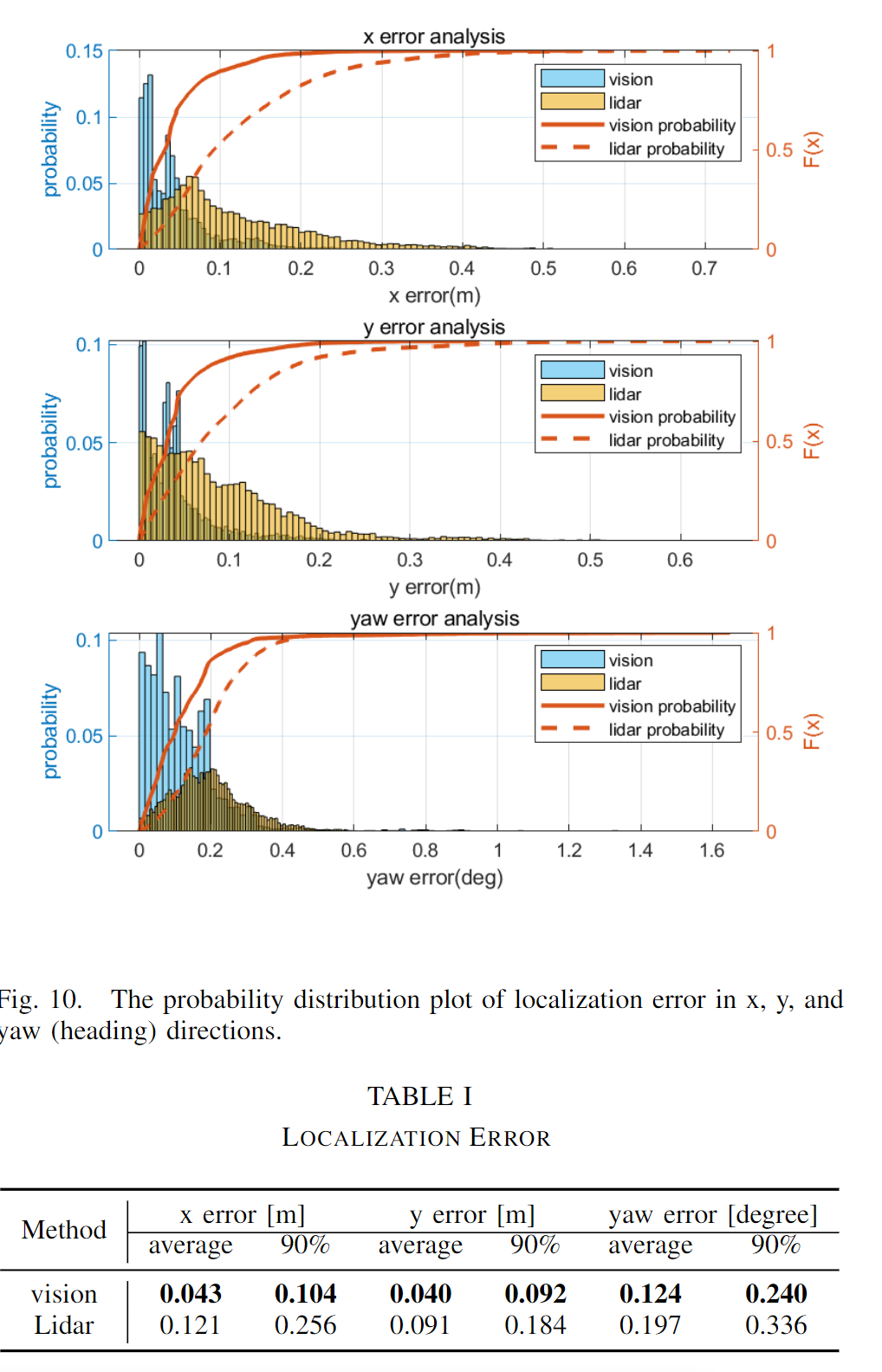
定位精度
对于定位精度的实验,作者和基于激光雷达的方案做对比,结果如下,可以看出整体结果略优于基于激光雷达的方法。
结论以及未来工作
作者提到一个改进的思路是除了车道线等平面特征以外可以将更多的 3D 特征利用起来。