使用概率对 SLAM 问题建模
考虑一个状态 $\boldsymbol{\xi}$ 和以及在这个状态量获得的一次观测 $\boldsymbol{r}$。由于噪声的存在,我们不能准确通过状态量计算出观测值,这个时候我们认为该观测服从一个条件概率分布:$p(\boldsymbol{r}|\boldsymbol{\xi})$。通过贝叶斯公式,有:
$$
p(\boldsymbol{\xi}|\boldsymbol{r}) = \frac{p(\boldsymbol{r}|\boldsymbol{\xi})p(\boldsymbol{\xi})}{p(\boldsymbol{r})}
$$
上式中,$p(\boldsymbol{\xi})$ 是状态量的先验概率,通常可以由一些传感器如 GPS 或者利用运动方程从上一时刻的状态量获得,$p(\boldsymbol{\xi}|\boldsymbol{r})$ 是在得到了当前观测量之后的状态量的后验概率。$p(\boldsymbol{r})$ 是观测值的概率,这个通常不会直接计算,如果我们已知状态量的先验概率密度函数,以及传感器的模型,我们根据以下方式计算:
$$
p(\boldsymbol{\xi}|\boldsymbol{r}) = \frac{p(\boldsymbol{r}|\boldsymbol{\xi})p(\boldsymbol{\xi})}{\int p(\boldsymbol{r}|\boldsymbol{\xi})p(\boldsymbol{\xi})d\boldsymbol{\xi}}
$$
通过上式计算出状态量的后验概率的过程叫贝叶斯推断,通常情况下我们并不会通过这个方式来对后验概率进行计算。
SLAM 要解决的问题是我们要估计出一个状态量 $\boldsymbol{\xi}^*$, 使得 $p(\boldsymbol{\xi}|\boldsymbol{r})$ 最大化,即求解以下式子:
$$
\boldsymbol{\xi}^* = \arg\max_{\boldsymbol{\xi}}p(\boldsymbol{\xi}|\boldsymbol{r})
$$
下面对式子进行化简,化简过程会省去与 $\boldsymbol{\xi}$ 无关的量:
$$
\begin{aligned}
\boldsymbol{\xi}^* &= \arg\max_{\boldsymbol{\xi}}p(\boldsymbol{\xi}|\boldsymbol{r})\\
&= \arg\max_{\boldsymbol{\xi}}\frac{p(\boldsymbol{r}|\boldsymbol{\xi})p(\boldsymbol{\xi})}{p(\boldsymbol{r})}\\
&= \arg\max_{\boldsymbol{\xi}}p(\boldsymbol{r}|\boldsymbol{\xi})p(\boldsymbol{\xi})\\
&= \arg\max_{\boldsymbol{\xi}}(\log{p(\boldsymbol{r}|\boldsymbol{\xi})} + \log{p(\boldsymbol{\xi})})\
\end{aligned}
$$
假设观测以及状态量都符合高斯分布,即:
$$
\begin{aligned}
\boldsymbol{x} &\sim N(\boldsymbol{u}, \boldsymbol{\Sigma})\\
p(\boldsymbol{x}) &= \frac{1}{\sqrt{(2\pi)^N\det{\boldsymbol{\Sigma}}}}\exp{\left(-\frac{1}{2}(\boldsymbol{x}-\boldsymbol{\mu})^T\boldsymbol{\Sigma}^{-1}(\boldsymbol{x}-\boldsymbol{\mu})\right)}
\end{aligned}
$$
对上式继续化简有:
$$
\begin{aligned}
\boldsymbol{\xi}^* &= \arg\max_{\boldsymbol{\xi}}p(\boldsymbol{r}|\boldsymbol{\xi})p(\boldsymbol{\xi})\\
&= \arg\max_{\boldsymbol{\xi}}{\left(\exp{\left(-\frac{1}{2}(\boldsymbol{r}-\boldsymbol{\mu}_r)^T\boldsymbol{\Sigma}_r^{-1}(\boldsymbol{r}-\boldsymbol{\mu}_r)\right)}\exp{\left(-\frac{1}{2}(\boldsymbol{\xi}-\boldsymbol{\mu}_{\xi})^T\boldsymbol{\Sigma}_{\xi}^{-1}(\boldsymbol{\xi}-\boldsymbol{\mu}_{\xi})\right)}\right)}\\
&= \arg\max_{\boldsymbol{\xi}}(\log{p(\boldsymbol{r}|\boldsymbol{\xi})} + \log{p(\boldsymbol{\xi})})\\
&= \arg\max_{\boldsymbol{\xi}}{\left({\left(-\frac{1}{2}(\boldsymbol{r}-\boldsymbol{\mu}_r)^T\boldsymbol{\Sigma}_r^{-1}(\boldsymbol{r}-\boldsymbol{\mu}_r)\right)}+ {\left(-\frac{1}{2}(\boldsymbol{\xi}-\boldsymbol{\mu}_{\xi})^T\boldsymbol{\Sigma}_{\xi}^{-1}(\boldsymbol{\xi}-\boldsymbol{\mu}_{\xi})\right)}\right)}\\
&= -\frac{1}{2}\arg\min_{\boldsymbol{\xi}}{\left({\left((\boldsymbol{r}-\boldsymbol{\mu}_r)^T\boldsymbol{\Sigma}_r^{-1}(\boldsymbol{r}-\boldsymbol{\mu}_r)\right)}+ {\left((\boldsymbol{\xi}-\boldsymbol{\mu}_{\xi})^T\boldsymbol{\Sigma}_{\xi}^{-1}(\boldsymbol{\xi}-\boldsymbol{\mu}_{\xi})\right)}\right)}\\
&= \arg\min_{\boldsymbol{\xi}}\left(||\boldsymbol{r}-\boldsymbol{\mu}_r||^2_{\boldsymbol{\Sigma}_r} + ||\boldsymbol{\xi}-\boldsymbol{\mu}_{\xi}||^2_{\boldsymbol{\Sigma}_{\xi}}\right)\\
\end{aligned}
$$
其中,$||\boldsymbol{x}-\boldsymbol{\mu}||^2_{\boldsymbol{\Sigma}} = (\boldsymbol{x}-\boldsymbol{\mu})^T\boldsymbol{\Sigma}^{-1}(\boldsymbol{x}-\boldsymbol{\mu})$
在有多个独立观测的情况下,上述式子变成为:
$$
\begin{aligned}
\boldsymbol{\xi}^* &= \arg\max_{\boldsymbol{\xi}}p(\boldsymbol{r}_1, \boldsymbol{r}_2, ..., \boldsymbol{r}_n |\boldsymbol{\xi})p(\boldsymbol{\xi})\\
&= \arg\max_{\boldsymbol{\xi}}\prod_ip(\boldsymbol{r_i}|\boldsymbol{\xi})p(\boldsymbol{\xi})\\
&= \arg\min_{\boldsymbol{\xi}}\left(\sum_i||\boldsymbol{r}_i-\boldsymbol{\mu}_{r_i}||^2_{\boldsymbol{\Sigma}_{r_i}} + ||\boldsymbol{\xi}-\boldsymbol{\mu}_{\xi}||^2_{\boldsymbol{\Sigma}_{\xi}}\right)\\
\end{aligned}
$$
这样,就将这个估计问题转变成一个最小二乘问题,可以通过最小二乘问题的方法进行求解了。
舒尔补在状态估计中的应用
问题引入
在估计状态量中的过程中,随着时间的推移,我们要估计的状态量可能也会越来越多,如在初始时刻我们估计的是:
$$
p(\boldsymbol{\xi}_0 | \boldsymbol{r}_0)
$$
随着时间的推移,,在引入很多新的状态量以及观测量之后,可能变成:
$$
p(\boldsymbol{\xi}_0, \boldsymbol{\xi}_1, ..., \boldsymbol{\xi}_n | \boldsymbol{r}_0, \boldsymbol{r}_1, ..., \boldsymbol{r}_m)
$$
这个时候如果我们还是直接求,可能计算量会越来越大,因此我们想要将一些较旧的状态量从估计问题中取掉,只估计最新的几个状态量。但是如果直接丢弃的化会将他们的约束也去掉了,可能影响我们估计结果的全局准确性,因此我们想要想一个方法在保持旧状态量的约束的同时将其从估计问题中去掉。
在第一部分中提到了,对 $\boldsymbol{xi}$ 的估计其实就是一个最小二乘问题,而最小二乘的问题的用高斯牛顿法的求解方法是:
$$
\begin{aligned}
\boldsymbol{J}^T\Sigma^{-1}\boldsymbol{J}\delta\boldsymbol{\xi} &= -\boldsymbol{J}^T\boldsymbol{\Sigma}^{-1}\boldsymbol{r}\\
\Rightarrow \boldsymbol{H}\delta\boldsymbol{\xi} &= \boldsymbol{b}
\end{aligned}
$$
其中 $\boldsymbol{J}$ 是残差对状态量的雅可比矩阵,$\boldsymbol{\Sigma}$ 是残差中涉及到的随机变量(状态量或者观测量)的协方差矩阵。
基于此,将我们要估计的状态量分为两部分,一部分是较旧的我们想去掉的,另一部分则是想保留的,则有:
$$
\begin{aligned}
\boldsymbol{H}\delta\boldsymbol{\xi} &= \boldsymbol{b}\\
\begin{bmatrix}
\boldsymbol{H}_{ii} & \boldsymbol{H}_{ij}\\
\boldsymbol{H}_{ji} & \boldsymbol{H}_{jj}
\end{bmatrix}
\begin{bmatrix}
\delta\boldsymbol{\xi}_i\\
\delta\boldsymbol{\xi}_j
\end{bmatrix} &=
\begin{bmatrix}
\boldsymbol{b}_i\\
\boldsymbol{b}_j
\end{bmatrix}
\end{aligned}
$$
我们想要做的是将 $\boldsymbol{\xi}_i$ 从估计的问题去掉(即将优化方程变成 $\boldsymbol{H}^*\delta\boldsymbol{\xi}_j = \boldsymbol{b}^*$)的同时,以某种方式将其对剩余状态量的约束也保留下来,使得 $\boldsymbol{H}^*\delta\boldsymbol{\xi}_j = \boldsymbol{b}^*_j$ 的最优解同时也是上面原式的最优解。这里会涉及到边缘化的方法,会在下一部分介绍。
舒尔补和边缘化原理
对于一个矩阵:
$$
\boldsymbol{M} = \begin{bmatrix}
\boldsymbol{A} & \boldsymbol{B} \\
\boldsymbol{C} & \boldsymbol{D}
\end{bmatrix}
$$
如果 $\boldsymbol{A}$ 或者 $\boldsymbol{D}$ 可逆,可以通过如下变换转换为上三角(或者下三角矩阵):
$$
\begin{aligned}
\begin{bmatrix}
\boldsymbol{I} & \boldsymbol{0}\\
-\boldsymbol{CA}^{-1} & \boldsymbol{I}
\end{bmatrix}
\begin{bmatrix}
\boldsymbol{A} & \boldsymbol{B} \\
\boldsymbol{C} & \boldsymbol{D}
\end{bmatrix} &= \begin{bmatrix}
\boldsymbol{A} & \boldsymbol{B}\\
\boldsymbol{0} & \Delta_{\boldsymbol{A}}
\end{bmatrix}\\
\begin{bmatrix}
\boldsymbol{A} & \boldsymbol{B} \\
\boldsymbol{C} & \boldsymbol{D}
\end{bmatrix}
\begin{bmatrix}
\boldsymbol{I} & \boldsymbol{0}\\
-\boldsymbol{D}^{-1}\boldsymbol{C} & \boldsymbol{I}
\end{bmatrix}
&= \begin{bmatrix}
\Delta_{D} & \boldsymbol{B}\\
\boldsymbol{0} & \boldsymbol{D}
\end{bmatrix}
\end{aligned}
$$
其中,$\Delta_{\boldsymbol{A}} = \boldsymbol{D} - \boldsymbol{CA}^{-1}\boldsymbol{B}, \Delta_{\boldsymbol{D}}=\boldsymbol{A} - \boldsymbol{BD}^{-1}\boldsymbol{C}$ 称为 $\boldsymbol{A}, \boldsymbol{D}$ 关于 $\boldsymbol{M}$ 的舒尔补。
利用舒尔补,我们可以对上一部分提到的的优化问题进行简化:
$$
\begin{aligned}
\begin{bmatrix}
\boldsymbol{H}_{ii} & \boldsymbol{H}_{ij}\\
\boldsymbol{H}_{ji} & \boldsymbol{H}_{jj}
\end{bmatrix}
\begin{bmatrix}
\delta\boldsymbol{\xi}_i\\
\delta\boldsymbol{\xi}_j
\end{bmatrix} &=
\begin{bmatrix}
\boldsymbol{b}_i\\
\boldsymbol{b}_j
\end{bmatrix}\\
\begin{bmatrix}
\boldsymbol{I} & \boldsymbol{0}\\
-\boldsymbol{H}_{ji}\boldsymbol{H}_{ii}^{-1} & \boldsymbol{I}
\end{bmatrix}
\begin{bmatrix}
\boldsymbol{H}_{ii} & \boldsymbol{H}_{ij}\\
\boldsymbol{H}_{ji} & \boldsymbol{H}_{jj}
\end{bmatrix}
\begin{bmatrix}
\delta\boldsymbol{\xi}_i\\
\delta\boldsymbol{\xi}_j
\end{bmatrix} &=
\begin{bmatrix}
\boldsymbol{I} & \boldsymbol{0}\\
-\boldsymbol{H}_{ji}\boldsymbol{H}_{ii}^{-1} & \boldsymbol{I}
\end{bmatrix}
\begin{bmatrix}
\boldsymbol{b}_i\\
\boldsymbol{b}_j
\end{bmatrix}\\
\begin{bmatrix}
\boldsymbol{H}_{ii} & \boldsymbol{H}_{ij}\\
\boldsymbol{0} & \boldsymbol{H}_{jj} - \boldsymbol{H}_{ji}\boldsymbol{H}_{\boldsymbol{ii}}^{-1}\boldsymbol{H}_{ij}
\end{bmatrix}
\begin{bmatrix}
\delta\boldsymbol{\xi}_i\\
\delta\boldsymbol{\xi}_j
\end{bmatrix} &=
\begin{bmatrix}
\boldsymbol{b}_i\\
-\boldsymbol{H}_{ji}\boldsymbol{H}^{-1}_{ii}\boldsymbol{b}_i + \boldsymbol{b}_j
\end{bmatrix}
\end{aligned}
$$
通过这个变换,我们可以将 $\boldsymbol{\xi}_i$ 从优化问题中剥离,将优化问题转为:
$$
\begin{aligned}
\boldsymbol{H}^*\Delta\boldsymbol{\xi}_j &= \boldsymbol{b}^*\\
(\boldsymbol{H}_{jj} - \boldsymbol{H}_{ji}\boldsymbol{H}_{\boldsymbol{ii}}^{-1})\Delta\boldsymbol{\xi}_j &= -\boldsymbol{H}_{ji}\boldsymbol{H}^{-1}_{ii}\boldsymbol{b}_i + \boldsymbol{b}_j
\end{aligned}
$$
舒尔补在多元高斯分布中的应用
考虑两个高斯分布:
$$
\begin{aligned}
p(\boldsymbol{x}) = \mathcal{N}(\boldsymbol{\mu}_x, \boldsymbol{\Sigma}_{xx})\\
p(\boldsymbol{y}) = \mathcal{N}(\boldsymbol{\mu}_y, \boldsymbol{\Sigma}_{yy})\\
\end{aligned}
$$
其联合概率分布为:
$$
p(\boldsymbol{x}, \boldsymbol{y}) = \mathcal{N}\left(
\begin{bmatrix}
\boldsymbol{\mu}_x\\
\boldsymbol{\mu}_y
\end{bmatrix},
\begin{bmatrix}
\boldsymbol{\Sigma}_{xx} & \boldsymbol{\Sigma}_{xy}\\
\boldsymbol{\Sigma}_{yx} & \boldsymbol{\Sigma}_{yy}
\end{bmatrix}
\right)
$$
我们想要做的是通过联合分布,来分离出先验和条件分布,即:
$$
p(\boldsymbol{x}, \boldsymbol{y}) = p(\boldsymbol{x}|\boldsymbol{y})p(\boldsymbol{y})
$$
首先利用舒尔补对协方差矩阵进行转换:
$$
\begin{bmatrix}
\boldsymbol{\Sigma}_{xx} & \boldsymbol{\Sigma}_{xy}\\
\boldsymbol{\Sigma}_{yx} & \boldsymbol{\Sigma}_{yy}
\end{bmatrix} =
\begin{bmatrix}
\boldsymbol{I} & \boldsymbol{\Sigma}_{xy}\boldsymbol{\Sigma}_{yy}^{-1}\\
\boldsymbol{0} & \boldsymbol{I}
\end{bmatrix}
\begin{bmatrix}
\boldsymbol{\Sigma}_{xx} - \boldsymbol{\Sigma}_{xy}\boldsymbol{\Sigma}_{yy}^{-1}\boldsymbol{\Sigma}_{yx} & \boldsymbol{0}\\
\boldsymbol{0} & \boldsymbol{\Sigma}_{yy}
\end{bmatrix}
\begin{bmatrix}
\boldsymbol{I} & \boldsymbol{0}\\
\boldsymbol{\Sigma}_{yy}^{-1}\boldsymbol{\Sigma}_{yx} & \boldsymbol{I}
\end{bmatrix}
$$
对协方差的逆也可以作类似分解:
$$
\begin{bmatrix}
\boldsymbol{\Sigma}_{xx} & \boldsymbol{\Sigma}_{xy}\\
\boldsymbol{\Sigma}_{yx} & \boldsymbol{\Sigma}_{yy}
\end{bmatrix} ^{-1} =
\begin{bmatrix}
\boldsymbol{I} & \boldsymbol{0}\\
-\boldsymbol{\Sigma}_{yy}^{-1}\boldsymbol{\Sigma}_{yx} & \boldsymbol{I}
\end{bmatrix}
\begin{bmatrix}
(\boldsymbol{\Sigma}_{xx} - \boldsymbol{\Sigma}_{xy}\boldsymbol{\Sigma}_{yy}^{-1}\boldsymbol{\Sigma}_{yx})^{-1} & \boldsymbol{0}\\
\boldsymbol{0} & \boldsymbol{\Sigma}_{yy}^{-1}
\end{bmatrix}
\begin{bmatrix}
\boldsymbol{I} & -\boldsymbol{\Sigma}_{xy}\boldsymbol{\Sigma}_{yy}^{-1}\\
\boldsymbol{0} & \boldsymbol{I}
\end{bmatrix}
$$
高斯分布的概率密度函数为:
$$
p(\boldsymbol{x}) = \frac{1}{(\sqrt{(2\pi)^{N}\det{\boldsymbol{\Sigma}})}}\exp{\left(-\frac{1}{2}(\boldsymbol{x}-\boldsymbol{\mu})^{T}\boldsymbol{\Sigma}^{-1}(\boldsymbol{x}-\boldsymbol{\mu})\right)}
$$
对上述联合分布的指数部分二次型展开:
$$
\begin{aligned}
&(\boldsymbol{x}-\boldsymbol{\mu})^{T}\boldsymbol{\Sigma}^{-1}(\boldsymbol{x}-\boldsymbol{\mu})\\
= &
\left(\begin{bmatrix}
\boldsymbol{x}\\
\boldsymbol{y}
\end{bmatrix} -
\begin{bmatrix}
\boldsymbol{\mu}_x\\
\boldsymbol{\mu}_y
\end{bmatrix}\right)^{T}
\begin{bmatrix}
\boldsymbol{\Sigma}_{xx} & \boldsymbol{\Sigma}_{xy}\\
\boldsymbol{\Sigma}_{yx} & \boldsymbol{\Sigma}_{yy}
\end{bmatrix}
\left(\begin{bmatrix}
\boldsymbol{x}\\
\boldsymbol{y}
\end{bmatrix} -
\begin{bmatrix}
\boldsymbol{\mu}_x\\
\boldsymbol{\mu}_y
\end{bmatrix}\right)\\
=&
\left(\begin{bmatrix}
\boldsymbol{x}\\
\boldsymbol{y}
\end{bmatrix} -
\begin{bmatrix}
\boldsymbol{\mu}_x\\
\boldsymbol{\mu}_y
\end{bmatrix}\right)^{T}
\begin{bmatrix}
\boldsymbol{I} & \boldsymbol{0}\\
-\boldsymbol{\Sigma}_{yy}^{-1}\boldsymbol{\Sigma}_{yx} & \boldsymbol{I}
\end{bmatrix}
\begin{bmatrix}
(\boldsymbol{\Sigma}_{xx} - \boldsymbol{\Sigma}_{xy}\boldsymbol{\Sigma}_{yy}^{-1}\boldsymbol{\Sigma}_{yx})^{-1} & \boldsymbol{0}\\
\boldsymbol{0} & \boldsymbol{\Sigma}_{yy}^{-1}
\end{bmatrix}
\begin{bmatrix}
\boldsymbol{I} & -\boldsymbol{\Sigma}_{xy}\boldsymbol{\Sigma}_{yy}^{-1}\\
\boldsymbol{0} & \boldsymbol{I}
\end{bmatrix}
\left(\begin{bmatrix}
\boldsymbol{x}\\
\boldsymbol{y}
\end{bmatrix} -
\begin{bmatrix}
\boldsymbol{\mu}_x\\
\boldsymbol{\mu}_y
\end{bmatrix}\right)\\
=&
\left(\begin{bmatrix}
\boldsymbol{x} - \boldsymbol{\mu}_x\\
\boldsymbol{y} - \boldsymbol{\mu}_y
\end{bmatrix}\right)^{T}
\begin{bmatrix}
\boldsymbol{I} & \boldsymbol{0}\\
-\boldsymbol{\Sigma}_{yy}^{-1}\boldsymbol{\Sigma}_{yx} & \boldsymbol{I}
\end{bmatrix}
\begin{bmatrix}
(\boldsymbol{\Sigma}_{xx} - \boldsymbol{\Sigma}_{xy}\boldsymbol{\Sigma}_{yy}^{-1}\boldsymbol{\Sigma}_{yx})^{-1} & \boldsymbol{0}\\
\boldsymbol{0} & \boldsymbol{\Sigma}_{yy}^{-1}
\end{bmatrix}
\begin{bmatrix}
\boldsymbol{I} & -\boldsymbol{\Sigma}_{xy}\boldsymbol{\Sigma}_{yy}^{-1}\\
\boldsymbol{0} & \boldsymbol{I}
\end{bmatrix}
\left(\begin{bmatrix}
\boldsymbol{x} - \boldsymbol{\mu}_x\\
\boldsymbol{y} - \boldsymbol{\mu}_y
\end{bmatrix}\right)\\
=&
\begin{bmatrix}
\boldsymbol{x} - \boldsymbol{\mu}_x -\boldsymbol{\Sigma}_{xy}\boldsymbol{\Sigma}_{yy}^{-1}(\boldsymbol{y} - \boldsymbol{\mu}_y)\\
\boldsymbol{y} - \boldsymbol{\mu}_y
\end{bmatrix}^T
\begin{bmatrix}
(\boldsymbol{\Sigma}_{xx} - \boldsymbol{\Sigma}_{xy}\boldsymbol{\Sigma}_{yy}^{-1}\boldsymbol{\Sigma}_{yx})^{-1} & \boldsymbol{0}\\
\boldsymbol{0} & \boldsymbol{\Sigma}_{yy}^{-1}
\end{bmatrix}
\begin{bmatrix}
\boldsymbol{x} - \boldsymbol{\mu}_x -\boldsymbol{\Sigma}_{xy}\boldsymbol{\Sigma}_{yy}^{-1}(\boldsymbol{y} - \boldsymbol{\mu}_y)\\
\boldsymbol{y} - \boldsymbol{\mu}_y
\end{bmatrix}\\
=&
(\boldsymbol{x} - (\boldsymbol{\mu}_x +\boldsymbol{\Sigma}_{xy}\boldsymbol{\Sigma}_{yy}^{-1}(\boldsymbol{y} - \boldsymbol{\mu}_y)))^T(\boldsymbol{\Sigma}_{xx} - \boldsymbol{\Sigma}_{xy}\boldsymbol{\Sigma}_{yy}^{-1}\boldsymbol{\Sigma}_{yx})^{-1}(\boldsymbol{x} - (\boldsymbol{\mu}_x +\boldsymbol{\Sigma}_{xy}\boldsymbol{\Sigma}_{yy}^{-1}(\boldsymbol{y} - \boldsymbol{\mu}_y))) + (\boldsymbol{y} - \boldsymbol{\mu}_y)^T\boldsymbol{\Sigma}_{yy}^{-1}(\boldsymbol{y} - \boldsymbol{\mu}_y)
\end{aligned}
$$
可以看到通过舒尔补我们将这个二次型分解成两个二次型的和,对应着两个高斯分布的乘积。右侧的那个从均值和协方差判断是 $p(\boldsymbol{y})$,因此左边的显然是 $p(\boldsymbol{x}|\boldsymbol{y})$,因此该条件概率服从以下高斯分布:
$$
p(\boldsymbol{x}|\boldsymbol{y}) = \mathcal{N}(\boldsymbol{\mu}_x + \boldsymbol{\Sigma}_{xy}\boldsymbol{\Sigma}_{yy}^{-1}(\boldsymbol{y} - \boldsymbol{\mu}_y), \boldsymbol{\Sigma}_{xx} - \boldsymbol{\Sigma}_{xy}\boldsymbol{\Sigma}_{yy}^{-1}\boldsymbol{\Sigma}_{yx})
$$
边缘化在 SLAM 中的应用
上面我们提到,SLAM 中的位姿估计实际上是求解一个最小二乘问题,这里我们假设一个最小二乘问题,如下所示:
$$
\boldsymbol{\xi} = \arg\min_{\boldsymbol{\xi}}\frac{1}{2}\sum_i|||\boldsymbol{r}_i||_{\boldsymbol{\Sigma}_i}^2
$$
其中涉及到的状态量共 6 个,残差关系如下图中的边所示,共 5 边:
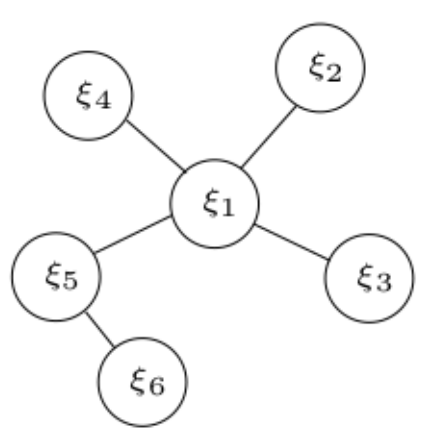
因此,状态量和残差分别可以表示为:
$$
\begin{aligned}
\boldsymbol{\xi} &= \begin{bmatrix}
\boldsymbol{\xi}_1 &
\boldsymbol{\xi}_2 &
\boldsymbol{\xi}_3 &
\boldsymbol{\xi}_4 &
\boldsymbol{\xi}_5 &
\boldsymbol{\xi}_6
\end{bmatrix}^T\\
\boldsymbol{r} &= \begin{bmatrix}
\boldsymbol{r}_{12} &
\boldsymbol{r}_{13} &
\boldsymbol{r}_{14} &
\boldsymbol{r}_{15} &
\boldsymbol{r}_{56}
\end{bmatrix}^T
\end{aligned}
$$
求解上述方程,通过高斯牛顿法可以转换为求解下述方程:
$$
\begin{aligned}
\boldsymbol{J}^T\Sigma^{-1}\boldsymbol{J}\delta\boldsymbol{\xi} &= -\boldsymbol{J}^T\boldsymbol{\Sigma}^{-1}\boldsymbol{r}\\
\Rightarrow \boldsymbol{H}\delta\boldsymbol{\xi} &= \boldsymbol{b}
\end{aligned}
$$
上式中,$\boldsymbol{\Sigma}$ 是一个对角矩阵,对角线上每个元素,各个残差的协方差矩阵,如下所示:
$$
\boldsymbol{\Sigma} = \begin{bmatrix}
\boldsymbol{\Sigma}_1 & \boldsymbol{0} & \boldsymbol{0} & \boldsymbol{0} & \boldsymbol{0}\\
\boldsymbol{0} & \boldsymbol{\Sigma}_2 & \boldsymbol{0} & \boldsymbol{0} & \boldsymbol{0}\\
\boldsymbol{0} & \boldsymbol{0} & \boldsymbol{\Sigma}_3 & \boldsymbol{0} & \boldsymbol{0}\\
\boldsymbol{0} & \boldsymbol{0} & \boldsymbol{0} & \boldsymbol{\Sigma}_4 & \boldsymbol{0}\\
\boldsymbol{0} & \boldsymbol{0} & \boldsymbol{0} & \boldsymbol{0} & \boldsymbol{\Sigma}_5\\
\end{bmatrix}
$$
$\boldsymbol{J}$ 为残差对各状态量的雅可比,对其展开有:
$$
\begin{aligned}
\boldsymbol{J} = \frac{\partial\boldsymbol{r}}{\partial\boldsymbol{\xi}}
= \begin{bmatrix}
\frac{\boldsymbol{r}_{12}}{\partial\boldsymbol{\xi}}\\
\frac{\boldsymbol{r}_{13}}{\partial\boldsymbol{\xi}}\\
\frac{\boldsymbol{r}_{14}}{\partial\boldsymbol{\xi}}\\
\frac{\boldsymbol{r}_{15}}{\partial\boldsymbol{\xi}}\\
\frac{\boldsymbol{r}_{56}}{\partial\boldsymbol{\xi}}\\
\end{bmatrix} = \begin{bmatrix}
\boldsymbol{J}_1
\boldsymbol{J}_2
\boldsymbol{J}_3
\boldsymbol{J}_4
\boldsymbol{J}_5
\end{bmatrix}
\end{aligned}
$$
因此,可以将待求解方程转换为累加形式:
$$
\begin{aligned}
\boldsymbol{H}\delta\boldsymbol{\xi} &= \boldsymbol{b}\\
\boldsymbol{J}^T\Sigma^{-1}\boldsymbol{J}\delta\boldsymbol{\xi} &= -\boldsymbol{J}^T\boldsymbol{\Sigma}^{-1}\boldsymbol{r}\\
\sum_{i=1}^5\boldsymbol{J}_i^T\boldsymbol{\Sigma}_i^{-1}\boldsymbol{J}_i\delta\boldsymbol{\xi} &= -\sum_{i=1}^5\boldsymbol{J}_i^T\boldsymbol{\Sigma}_i^{-1}\boldsymbol{r}_i\\
\Rightarrow \boldsymbol{H} &= \sum_{i=1}^5\boldsymbol{J}_i^T\boldsymbol{\Sigma}_i^{-1}\boldsymbol{J}_i = \sum_i\boldsymbol{H}_i\\
\Rightarrow \boldsymbol{b} &= -\sum_{i=1}^5\boldsymbol{J}_i^T\boldsymbol{\Sigma}_i^{-1}\boldsymbol{r}_i = \sum_i\boldsymbol{b}_i
\end{aligned}
$$
通常情况下,残差只与当前估计的少数状态量相关,所以他的形式是稀疏的,因此相加得到的信息矩阵也是稀疏的,如下图所示:
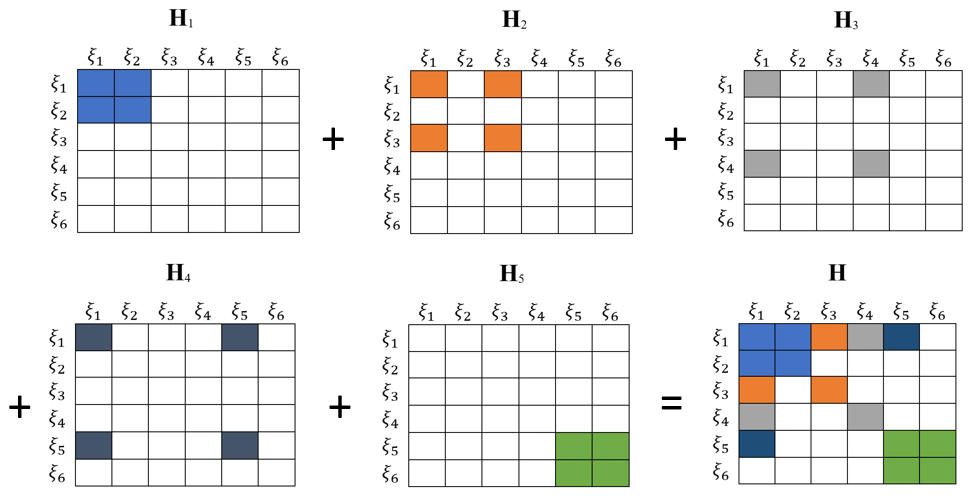
假设我们现在想要去掉最老的一个状态量,即 $\boldsymbol{\xi}_i$。首先将 $\boldsymbol{H}$ 分为四个部分:
$$
\begin{aligned}
\boldsymbol{H} = \begin{bmatrix}
\boldsymbol{H}_{\alpha\alpha} & \boldsymbol{H}_{\beta\alpha} \\
\boldsymbol{H}_{\alpha\beta} & \boldsymbol{H}_{\beta\beta}
\end{bmatrix}
\end{aligned}
$$
上式中,$\boldsymbol{H}_{\alpha\alpha}$ 为 $1\times1$ 矩阵,其他依次类推。按照前一部分提到的边缘化方法我们可以对 $\boldsymbol{H}$ 进行以下变换,
$$
\begin{aligned}
\boldsymbol{H}^* = \boldsymbol{H}_{\beta\beta} - \boldsymbol{H}_{\alpha\beta}\boldsymbol{H}_{\alpha\alpha}^{-1}\boldsymbol{H}_{\beta\alpha}
\end{aligned}
$$
反映到具体矩阵元素上,有:
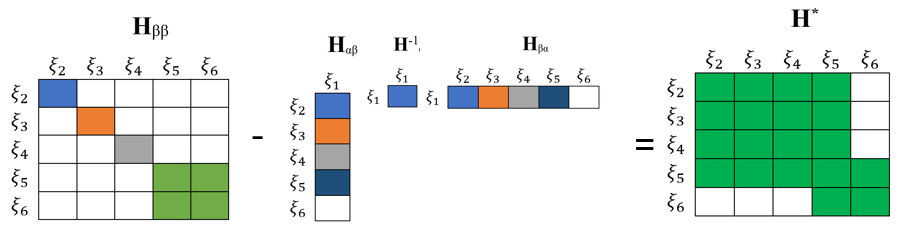
此时如果我们看节点图,在去除了一个节点之后,我们相当于在剩下的节点中加了很多边,如下所示:

在实际使用的时候,我们会将上述变换分成两部分:
$$
\begin{aligned}
&(\boldsymbol{H}_{\beta\beta} - \boldsymbol{H}_{\alpha\beta}\boldsymbol{H}_{\alpha\alpha}^{-1}\boldsymbol{H}_{\beta\alpha})\delta\boldsymbol{\xi} = \boldsymbol{b}_{\beta} - \boldsymbol{H}_{\alpha\beta}\boldsymbol{H}_{\alpha\alpha}^{-1}\boldsymbol{b}_{\alpha}\\
\Rightarrow
&\left\{
\begin{aligned}
\boldsymbol{H}_{\beta\beta}\delta\boldsymbol{\xi}&= \boldsymbol{b}_{\beta}\\
- \boldsymbol{H}_{\alpha\beta}\boldsymbol{H}_{\alpha\alpha}^{-1}\boldsymbol{H}_{\beta\alpha}\delta\boldsymbol{\xi} &= - \boldsymbol{H}_{\alpha\beta}\boldsymbol{H}_{\alpha\alpha}^{-1}\boldsymbol{b}_{\alpha}
\end{aligned}
\right.
\end{aligned}\\
$$
从中分离出来的一部分可以看作是丢弃的节点对剩余状态量的信息,我们同样可以反解出它的残差与雅可比,我们把这一部分残差称为先验观测(以及残差),从图中不难看出,先验残差与 $\boldsymbol{\xi}_{2:5}$ 有关。
假如这个时候加入一个新的节点,其对应的观测如下图所示:
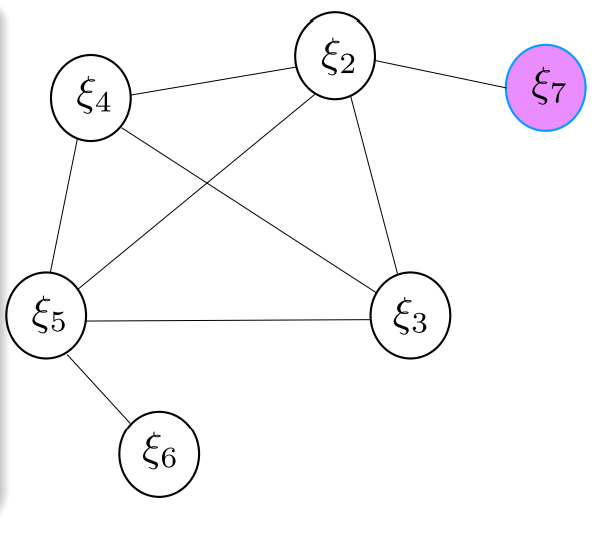
不难看出,我们需要加一个由 2 7 节点之间观测得到的残差对应的信息矩阵,信息矩阵中只有 2 7 相关的部分有元素,如下图所示:
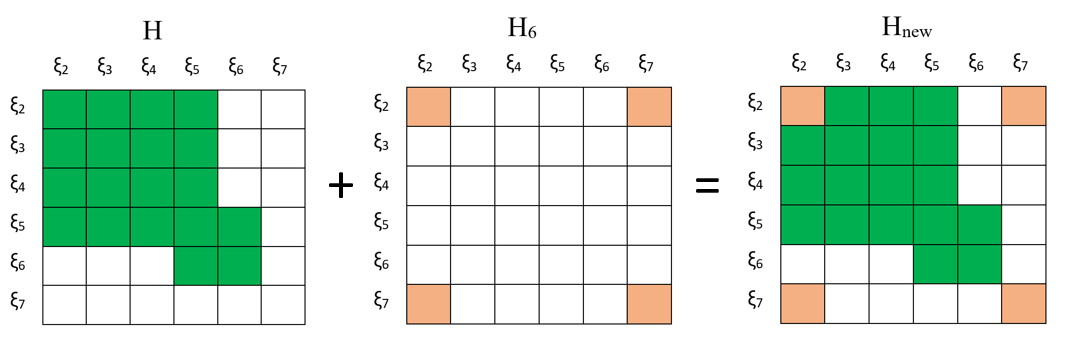
通过这样,我们完成了去除一个估计量以及增加一个估计量使得整体的估计问题规模不变,大致的顺序为:
$t$时刻,有$\boldsymbol{\xi}_{1:6}$6 个状态量以及$\boldsymbol{r}_{1:5}$5 个观测量(以及对应残差)- 在完成最小二乘优化之后,将
$\boldsymbol{\xi}_1$及其相关的残差$\boldsymbol{r}_{1:4}$通过边缘化去掉,更新先验信息$\boldsymbol{r}_p$,剩余状态量有$\boldsymbol{\xi}_{2:6}$, 与$\boldsymbol{\xi}_1$相关的信息通过边缘化传递给了$\boldsymbol{\xi}_{2:5}$,$\boldsymbol{\xi}_6$不受影响 $t+1$时刻,将新的状态量$\boldsymbol{\xi}_7$以及对应的观测$\boldsymbol{r}_6$和上一时刻剩下的$\boldsymbol{\xi}_{2:6}$,相应的观测$\boldsymbol{r}_5$以及先验信息$\boldsymbol{r}_p$加入图中,进入新一轮优化。
边缘化可能引起的问题
在边缘化的过程中可能会导致一些问题,下面进行整理。
信息矩阵的稀疏性
从上面的例子可以看到,在进行边缘化之后,信息矩阵的稀疏性被破坏了,这在优化状态量较少的时候不会有很大影响,但是在优化量较多的时候可能会影响性能,例如在 vslam 需要同时估计路标点以及载体状态的时候。在这种情况下,需要按照具体情况进行一些操作来保持矩阵的稀疏性,保证方程求解的快速性。(待补充)
新旧信息融合时产生的问题
滑动窗口算法优化的时候,信息矩阵以及残差分成了两部分,分别是通过边缘化去除了旧的状态量后留下的先验部分,以及剩下的其他部分。上面提到,对于先验部分的信息矩阵,我们同样可以反解出其对应的雅可比矩阵和残差向量,但由于相关的状态量以及观测值我们已经去掉了,所以这部分雅可比矩阵在后续没有办法进行更新(计算雅可比同时需要估计值和观测值),因此相当于对于这一部分的残差,其线性化点固定在边缘化之前的状态量处。这样通常来说是没问题的,但从上面的例子可以看到,对于先验残差,它涉及到的的状态量有可能也会被新的残差涉及( 如上面例子中的 $\boldsymbol{\xi}_2$ 除了在先验残差 $\boldsymbol{r}_p$ 里面也在 $\boldsymbol{r}_{6}$ 里面),假如我们不做特别处理,在进行后续优化过程中,新的残差对应的雅可比矩阵会随着状态量的更新而更新,相当于新的残差 ($\boldsymbol{r}_6$) 的线性点也在一直变化。即在涉及到同一个状态量的不同雅可比的线性点不一致,这会给信息矩阵引入错误信息。
解决方法可以是,保持对同一个状态量对残差进行线性化时保持线性化点一致,即在求新的残差及其雅可比时,涉及到先验残差里面的状态量时使用先验残差求雅可比时使用的状态量。但是注意对于先验信息的残差部分我们是可以根据新估计的状态量来进行更新的,这就是 First Estimiated Jacobian (FEJ)算法。概括一下,对于先验部分,其雅可比 $\boldsymbol{J}_p$ 以及相当于信息矩阵 $\boldsymbol{H}_p$ 在优化过程保持不变,残差 $\boldsymbol{r}_p$ 以及和残差相关的 $\boldsymbol{b}_p$ 会随着状态量的更新而改变。
对于新的先验残差怎么根据状态量的变化更新,由于观测值已经丢失了所以没办法直接计算,可以进行一阶泰勒进行线性化计算,如下所示:
$$
\boldsymbol{r}_p^* = \boldsymbol{r}_p + \frac{\partial\boldsymbol{r}_p}{\partial\boldsymbol{x}_p}\delta\boldsymbol{x} = \boldsymbol{r}_p + \boldsymbol{J}_p\delta\boldsymbol{x}
$$
对 $\boldsymbol{b}_p$ 也是类似原理:
$$
\begin{aligned}
\boldsymbol{b}_p^* &= \boldsymbol{b}_p + \frac{\partial\boldsymbol{b}_p}{\partial\boldsymbol{x}_p}\delta\boldsymbol{x}\\
&= \boldsymbol{b}_p + \frac{\partial(-\boldsymbol{J}_p^T\boldsymbol{\Sigma}^{-1}\boldsymbol{r})}{\partial\boldsymbol{x}_p}\delta\boldsymbol{x}\\
&= \boldsymbol{b}_p + (-\boldsymbol{J}_p^T\boldsymbol{\Sigma}^{-1}\boldsymbol{J}_p)\delta\boldsymbol{x}\\
&= \boldsymbol{b}_p - \boldsymbol{H}_p\delta\boldsymbol{x}
\end{aligned}
$$