最小二乘问题
在求解 SLAM 中的最优状态估计问题时,我们一般会得到两个变量,一个是由传感器获得的实际观测值 $\boldsymbol{z}$,一个是根据目前估计的状态量和观测模型计算出来的预测值 $h(\boldsymbol{x})$。求解最优状态估计问题时通常我们会尝试最小化预测值和观测值计算出的残差平方(使用平方是为了统一正负号的影响),即求解以下最小二乘问题:
$$
\boldsymbol{x}^* = \arg\min_{\boldsymbol{x}}||\boldsymbol{z} - h(\boldsymbol{x})||^2
$$
如果观测模型是线性模型,则上式转化为线性最小二乘问题:
$$
\boldsymbol{x}^* = \arg\min_{\boldsymbol{x}}||\boldsymbol{z} - \boldsymbol{H}\boldsymbol{x}||^2
$$
对于线性最小二乘问题,我们可以直接求闭式解:$\boldsymbol{x}^* = -(\boldsymbol{H}^T\boldsymbol{H})^{-1}\boldsymbol{H}^T\boldsymbol{z}$ 这里不进行赘述。
实际的问题中,我们通常要最小化不止一个残差,不同残差通常会按其重要性(不确定性)分配一个相应的权重系数,且观测模型也通常是非线性的,即求解以下问题:
$$
\begin{aligned}
\boldsymbol{e}_i(\boldsymbol{x}) &= \boldsymbol{z}_i - h_i(\boldsymbol{x}) \qquad i = 1, 2, ..., n\\
||\boldsymbol{e}_i(\boldsymbol{x})||^2_{\Sigma_i} &= \boldsymbol{e}_i^T\boldsymbol{\Sigma}_i\boldsymbol{e}_i\\
\boldsymbol{x}^* &= \arg\min_{\boldsymbol{x}}F(\boldsymbol{x})\\
&= \arg\min_{\boldsymbol{x}}\sum_i||\boldsymbol{e}_i(\boldsymbol{x})||^2_{\Sigma_i}
\end{aligned}
$$
我们想要获得一个状态量 $\boldsymbol{x}^*$,使得损失函数 $F(\boldsymbol{x})$ 取得局部最小值。
在具体求解之前,先考虑 $F(\boldsymbol{x})$ 的性质,对其进行二阶泰勒展开:
$$
F(\boldsymbol{x} + \Delta\boldsymbol{x}) = F(\boldsymbol{x}) + \boldsymbol{J}\Delta\boldsymbol{x} + \frac{1}{2}\Delta\boldsymbol{x}^T\boldsymbol{H}\Delta\boldsymbol{x} + O(||\Delta\boldsymbol{x}||^3)
$$
忽略高阶余项,对二次函数,有以下性质:
如果在点 $\boldsymbol{x}^*$ 处,导数为 $\boldsymbol{0}$,则这个点为稳定点,根据 Hessian 矩阵的正定性有不同性质:
- 如果
$\boldsymbol{H}$为正定矩阵,则$F(\boldsymbol{x}^*)$为局部最小值 - 如果
$\boldsymbol{H}$为负定矩阵,则$F(\boldsymbol{x}^*)$为局部最大值 - 如果
$\boldsymbol{H}$为不定矩阵,则$F(\boldsymbol{x}^*)$为鞍点
在实际过程中,一般 $F(x)$ 比较复杂,我们没有办法直接使其导数为 0 进而求出该点,因此常用的是迭代法,即找到一个下降方向使损失函数随 $\boldsymbol{x}$ 的迭代逐渐减少,直到 $\boldsymbol{x}$ 收敛到 $\boldsymbol{x}^*$。下面整理以下常用的几种迭代方法。
迭代下降法
上面提到,我们需要找到一个 $\boldsymbol{x}$ 的迭代量使得 $F(\boldsymbol{x})$ 减少。这个过程分两步:
- 找到
$\boldsymbol{F(x)}$的下降方向,构建该方向的单位向量$\boldsymbol{d}$ - 确定该方向的迭代步长
$\alpha$
迭代后的自变量 $\boldsymbol{x} + \alpha\boldsymbol{d}$ 对应的函数值可以用一阶泰勒展开近似(当步长足够小的时候):
$$
F(\boldsymbol{x} + \alpha\boldsymbol{d}) = F(\boldsymbol{x}) + \alpha\boldsymbol{Jd}
$$
因此,不难发现,要保持 $F(x)$ 是下降的,只需要保证 $\boldsymbol{Jd} < 0$。以下几种方法都是以不同思路在寻找一个合适的方向进行迭代。
最速下降法
基于上一部分,我们知道变化量为 $\alpha\boldsymbol{Jd}$,其中 $\boldsymbol{Jd} = ||\boldsymbol{J}||\cos{\theta}$,$\theta$ 为梯度$\boldsymbol{J}$ 和 $\boldsymbol{d}$ 的夹角。当 $\theta = -\pi$ 时,$\boldsymbol{Jd} = -||\boldsymbol{J}||$ 取得最小值,此时方向向量为:
$$
\boldsymbol{d} = \frac{-\boldsymbol{J}^T}{||\boldsymbol{J}||}
$$
因此,沿梯度 $\boldsymbol{J}$ 的负方向可以使 $F(\boldsymbol{x})$,但实际过程中,一般只会在迭代刚开始使用这种方法,当接近最优值时这种方法会出现震荡并且收敛较慢。
牛顿法
对 $F(\boldsymbol{x})$ 进行二阶泰勒展开:
有:
$$
F(\boldsymbol{x} + \Delta\boldsymbol{x}) = F(\boldsymbol{x}) + \boldsymbol{J}\Delta\boldsymbol{x} + \frac{1}{2}\Delta\boldsymbol{x}^T\boldsymbol{H}\Delta\boldsymbol{x}
$$
我们关注的是求一个 $\Delta\boldsymbol{x}$ 使得 $\boldsymbol{J}\Delta\boldsymbol{x} + \frac{1}{2}\Delta\boldsymbol{x}^T\boldsymbol{H}\Delta\boldsymbol{x}$ 最小,因此可以求导得:
$$
\begin{aligned}
\frac{\partial(\boldsymbol{J}\Delta\boldsymbol{x} + \frac{1}{2}\Delta\boldsymbol{x}^T\boldsymbol{H}\Delta\boldsymbol{x})}{\partial\Delta\boldsymbol{x}} &= \boldsymbol{J}^T + \boldsymbol{H}\Delta\boldsymbol{x} = 0\\
\Rightarrow \Delta\boldsymbol{x} &= -\boldsymbol{H}^{-1}\boldsymbol{J}^T
\end{aligned}
$$
当 $\boldsymbol{H}$ 为正定矩阵且当前 $\boldsymbol{x}$ 在最优点附近时,取 $\Delta\boldsymbol{x} = -\boldsymbol{H}^{-1}\boldsymbol{J}^T$ 可以使函数获得局部最小值。但缺点是残差的 Hessian 函数通常比较难求。
阻尼法
在牛顿法的基础上,为了控制每次迭代不要太激进,我们可以在损失函数中增加一项惩罚项,如下所示:
$$
\arg\min_{\Delta\boldsymbol{x}}\left\{F(\boldsymbol{x}) + \boldsymbol{J}\Delta\boldsymbol{x} + \frac{1}{2}\Delta\boldsymbol{x}^T\boldsymbol{H}\Delta\boldsymbol{x} + \frac{1}{2}\mu(\Delta\boldsymbol{x})^T(\Delta\boldsymbol{x})\right\}
$$
当我们选的 $\Delta\boldsymbol{x}$ 太大时,损失函数也会变大,变大的幅度由 $\mu$ 决定,因此我们可以控制每次迭代量 $\Delta\boldsymbol{x}$ 的大小。同样在右侧部分对 $\Delta\boldsymbol{x}$ 求导有:
$$
\begin{aligned}
\boldsymbol{J}^T + \boldsymbol{H}\Delta\boldsymbol{x} + \mu\Delta\boldsymbol{x} &= 0\\
(\boldsymbol{H} + \mu\boldsymbol{I})\Delta\boldsymbol{x} = -\boldsymbol{J}^T
\end{aligned}
$$
这个思路我们后面在介绍 LM 法时也会用到。
高斯牛顿(GN)法
在第一部分的整理中实际上我们要求解的是一系列残差的和,求单个残差的雅可比比较简单,因此在后续的几种方法中我们关注各个残差的变化。将上述非线性最小二乘问题中的各个残差写成向量形式:
$$
\boldsymbol{E}(\boldsymbol{x}) =\begin{bmatrix}
\boldsymbol{e}_1(\boldsymbol{x})\\
\boldsymbol{e}_2(\boldsymbol{x})\\
...\\
\boldsymbol{e}_n(\boldsymbol{x})\\
\end{bmatrix}
$$
因此,$F(\boldsymbol{x})$ 可以表示为:
$$
F(\boldsymbol{x}) = \boldsymbol{E}(\boldsymbol{x})^T\boldsymbol{E}(\boldsymbol{x}) = \sum_i\boldsymbol{e}_i(\boldsymbol{x})^T\boldsymbol{e}(\boldsymbol{x})
$$
对 $\boldsymbol{E}(\boldsymbol{x})$ 进行泰勒展开,有:
$$
\boldsymbol{E}(\boldsymbol{x} + \Delta\boldsymbol{x}) = \boldsymbol{E}(\boldsymbol{x}) + \boldsymbol{J}\Delta\boldsymbol{x}
$$
上式中,$\boldsymbol{J}$ 是残差矩阵 $\boldsymbol{E}(\boldsymbol{x})$ 对状态量的雅可比矩阵。
注意到在原来的线性最小二乘问题中,对每个残差还有一个权重矩阵 $\boldsymbol{\Sigma}$。这种情况下,我们只需要令 $\boldsymbol{e}_i(\boldsymbol{x}) = \sqrt{\boldsymbol{\Sigma}_i}\boldsymbol{e}_i(\boldsymbol{x})$ 即可。因此下式中暂不考虑 $\boldsymbol{\Sigma}$ 的影响。
在这种形式下对 $F(\boldsymbol{x})$ 进行二阶泰勒展开,有:
$$
\begin{aligned}
F(\boldsymbol{x} + \Delta\boldsymbol{x}) &= \boldsymbol{E}(\boldsymbol{x} + \Delta\boldsymbol{x})^T\boldsymbol{E}(\boldsymbol{x} + \Delta\boldsymbol{x})\\
&= (\boldsymbol{E}(\boldsymbol{x}) + \boldsymbol{J}\Delta\boldsymbol{x})^T(\boldsymbol{E}(\boldsymbol{x}) + \boldsymbol{J}\Delta\boldsymbol{x})\\
&= \boldsymbol{E}(\boldsymbol{x})^T\boldsymbol{E}(\boldsymbol{x}) + \Delta\boldsymbol{x}^T\boldsymbol{J}^T\boldsymbol{E}(\boldsymbol{x}) + \boldsymbol{E}(\boldsymbol{x})^T\boldsymbol{J}\Delta\boldsymbol{x} + \Delta\boldsymbol{x}^T\boldsymbol{J}^T\boldsymbol{J}\Delta\boldsymbol{x}
\end{aligned}
$$
上式中,注意到:$F(\boldsymbol{x})$ 是一维的,因此 $\Delta\boldsymbol{x}^T\boldsymbol{J}^T\boldsymbol{E}(\boldsymbol{x}) = \boldsymbol{E}(\boldsymbol{x})^T\boldsymbol{J}\Delta\boldsymbol{x}$,因此化简得:
$$
\begin{aligned}
F(\boldsymbol{x} + \Delta\boldsymbol{x}) &= \boldsymbol{E}(\boldsymbol{x})^T\boldsymbol{E}(\boldsymbol{x}) + 2\boldsymbol{E}(\boldsymbol{x})^T\boldsymbol{J}\Delta\boldsymbol{x} + \Delta\boldsymbol{x}^T\boldsymbol{J}^T\boldsymbol{J}\Delta\boldsymbol{x}\\
&= F(\boldsymbol{x}) + 2\boldsymbol{E}(\boldsymbol{x})^T\boldsymbol{J}\Delta\boldsymbol{x} + \Delta\boldsymbol{x}^T\boldsymbol{J}^T\boldsymbol{J}\Delta\boldsymbol{x}
\end{aligned}
$$
通过这种方式,我们同样将其近似一个二次函数,并且和我们之前展开的结果比较,不难发现在这里我们实际上是用 $\boldsymbol{J}^T\boldsymbol{E}$ 来近似 Jacobian 矩阵,用 $\boldsymbol{J}^T\boldsymbol{J}$ 来近似 Hessian 矩阵。因此,当 $\boldsymbol{J}$ 满秩时,我们可以保证在上式导数为 0 的地方可以确保函数取得局部最小值。同样,在上式右侧部分对 $\Delta\boldsymbol{x}$ 求导并使其为 0 有:
$$
\begin{aligned}
\boldsymbol{J}^T\boldsymbol{E}(\boldsymbol{x}) + \boldsymbol{J}^T\boldsymbol{J}\Delta\boldsymbol{x} = 0\\
\Rightarrow \boldsymbol{J}^T\boldsymbol{J}\Delta\boldsymbol{x} &= -\boldsymbol{J}^T\boldsymbol{E}(\boldsymbol{x})\\
\Rightarrow \boldsymbol{H}\Delta\boldsymbol{x} &= \boldsymbol{b}
\end{aligned}
$$
上式中,我们令 $\boldsymbol{H} = \boldsymbol{J}^T\boldsymbol{J}, \boldsymbol{b} = -\boldsymbol{J}^T\boldsymbol{E}$。这样我们获得了高斯牛顿法的求解过程:
- 计算残差矩阵关于状态值的雅可比矩阵
$\boldsymbol{J}$ - 利用雅可比矩阵和残差构建信息矩阵和信息向量
$\boldsymbol{H}, \boldsymbol{b}$ - 计算当次迭代量:
$\Delta\boldsymbol{x} = \boldsymbol{H}^{-1}\boldsymbol{b}$ - 如果迭代量足够小则结束迭代,否则进入下一次迭代
莱文贝格马夸特(LM)法
LM 法是在高斯牛顿法的基础上按照阻尼法的思路加入阻尼因子,即求解以下方程:
$$
(\boldsymbol{H} + \mu\boldsymbol{I})\Delta\boldsymbol{x} = \boldsymbol{b}
$$
上式中,阻尼因子的作用有:
- 添加进
$\boldsymbol{H}$保证$\boldsymbol{H}$是正定的 - 当
$\mu$很大时,$\Delta\boldsymbol{x} = -(\boldsymbol{H}+\mu\boldsymbol{I})^{-1}\boldsymbol{b}\approx-\frac{1}{\mu}\boldsymbol{b}=-\frac{1}{\mu}\boldsymbol{J}^T\boldsymbol{E}(\boldsymbol{x})$,接近最速下降法 - 当
$\mu$很小时,则接近高斯牛顿法
因此,合理的设置阻尼因子,能够达到动态对迭代速度进行调节。阻尼因子的设置分为两部分:
- 初始值的选取
- 随迭代量变化的更新策略
先来看初始值选取方法,阻尼因子的大小应该根据 $\boldsymbol{J}^T\boldsymbol{J}$ 的大小来选取,对 $\boldsymbol{J}^T\boldsymbol{J}$ 进行特征值分解,有:$\boldsymbol{J}^T\boldsymbol{J} = \boldsymbol{V}\boldsymbol{\Lambda}\boldsymbol{V}^T$,$\boldsymbol{\Lambda} = \text{diag}(\lambda_1, \lambda_2,..., \lambda_n), \boldsymbol{V} = [\boldsymbol{v}_1, ..., \boldsymbol{v}_n]$,因此,迭代公式化简为:
$$
\begin{aligned}
(\boldsymbol{V\Lambda}\boldsymbol{V}^T + \mu\boldsymbol{I})\Delta\boldsymbol{x} &= \boldsymbol{b}\\
\Delta\boldsymbol{x} &= (\boldsymbol{V\Lambda}\boldsymbol{V}^T + \mu\boldsymbol{I})^{-1}\boldsymbol{b}\\
&= -\sum_i\frac{\boldsymbol{v}_i^T\boldsymbol{b}}{\lambda_i + \mu}\boldsymbol{v}_i
\end{aligned}
$$
因此,将 $\mu$ 选为 $\lambda_i$ 接近即可,一个简单的思路是设 $\mu_0 = \tau\max{(\boldsymbol{J}^T\boldsymbol{J})_{ii}}$,实际中一般设 $\tau \approx [10^{-8}, 1]$
接下来看 $\mu$ 的更新策略,先定性分析应该怎么更新阻尼因子:
- 当
$\Delta\boldsymbol{x}$令$F(\boldsymbol{x})$增加时,应该提高$\mu$来降低$\Delta\boldsymbol{x}$即通过减少步长来降低本次迭代带来的影响 - 当
$\Delta\boldsymbol{x}$令$F(\boldsymbol{x})$减少时,应该降低$\mu$来提高$\Delta\boldsymbol{x}$即通过增加步长来提高这次迭代的影响
下面进行定量分析,令 $L(\Delta\boldsymbol{x}) = F(\boldsymbol{x}) +2\boldsymbol{E}(\boldsymbol{x})^T\boldsymbol{J}\Delta\boldsymbol{x} + \frac{1}{2}\Delta\boldsymbol{x}^T\boldsymbol{J}^T\boldsymbol{J}\Delta\boldsymbol{x}$考虑以下比例因子:
$$
\rho = \frac{F(\boldsymbol{x}) - F(\boldsymbol{x} + \Delta\boldsymbol{x})}{L(\boldsymbol{0}) - F(\Delta\boldsymbol{x})}
$$
Marquardt 提出一个策略:
- 当
$\rho < 0$,表示当前$\Delta\boldsymbol{x}$使$F(\boldsymbol{x})$增大,表示离最优值还很远,应该提高$\mu$使其接近最速下降法进行较大幅度的更新 - 当
$\rho > 0$且比较大,表示当前$\Delta\boldsymbol{x}$使$F(\boldsymbol{x})$减小,应该降低$\mu$使其接近高斯牛顿法,降低速度更新至最优点 - 如果
$\rho > 0$但比较小,表示已经到最优点附近,则增大阻尼$\mu$,缩小迭代步长
Marquardt 的具体策略如下:
if rho < 0.25:
mu = mu * 2
else if rho > 0.75:
mu = mu /3
一个使用 Marquardt 策略进行更新的过程如下:
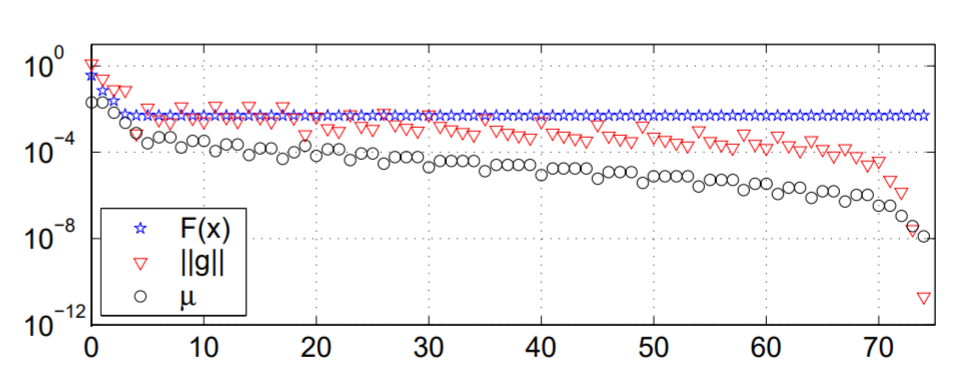
可以发现,效果并不算很好,随着迭代次数的增加,$\mu$ 开始进行震荡,表示迭代量周期性的使 $F(\boldsymbol{x})$ 增加又下降。
因此,Nielsen 提出了另一个策略,也是 G2O 和 Ceres 中使用的策略:
if rho > 0:
mu = mu * max(1/3, 1 - (2 * rho - 1)^3)
v = 2
else:
mu = mu * v
v = 2 * v
使用这种策略进行优化的例子如下:
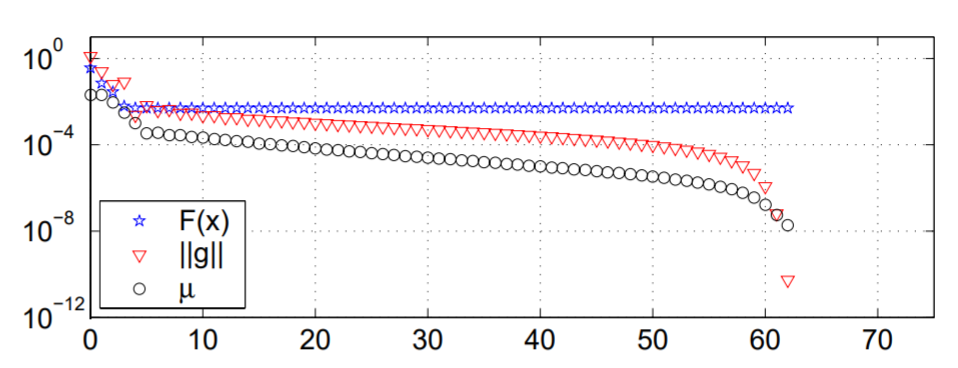
可以看到,$\mu$ 随着迭代的进行可以比较平滑的持续下降直至达到收敛。
鲁棒核函数
在进行最小二乘问题中,我们会遇到一些异常观测值使得观测残差特别大,如果不对这些异常点做处理会影响在优化过程中,优化器会尝试最小化异常的残差项,最后影响状态估计的精度,鲁棒核函数就是用来降低这些异常观测值造成的影响。
将鲁棒核函数直接作用在每个残差项上,将最小二乘问题变成如下形式:
$$
F(\boldsymbol{x}) = \sum_i\rho(||e_i(\boldsymbol{x})||^2)
$$
使用鲁棒核函数时求解非线性最小二乘的过程
在这个形式下对带有鲁棒核函数的残差进行二阶泰勒展开:
$$
\rho(s + \Delta s) = \rho(x) + \rho'(x)\Delta s + \frac{1}{2}\rho''(x)\Delta^2s
$$
上式中,变化量 $\Delta s$ 的计算方式如下:
$$
\begin{aligned}
\Delta s_k &= ||e_i(\boldsymbol{x}+\Delta\boldsymbol{x})||^2 - ||e_i(\boldsymbol{x})||^2\\
&= ||e_i(\boldsymbol{x})+\boldsymbol{J}_i\Delta\boldsymbol{x}||^2 - ||e_i(\boldsymbol{x})||^2\\
&= 2e_i(\boldsymbol{x})^T\boldsymbol{J}_i\Delta\boldsymbol{x}+\Delta\boldsymbol{x}^T\boldsymbol{J}_i^T\boldsymbol{J}_i\Delta\boldsymbol{x}
\end{aligned}
$$
将 $\Delta s$ 代入 $\rho(s + \Delta s)$ 可得:
$$
\begin{aligned}
\rho(s + \Delta s) =& \rho(s) + \rho'(s)(2e_i(\boldsymbol{x})^T\boldsymbol{J}_i\Delta\boldsymbol{x}+\Delta\boldsymbol{x}^T\boldsymbol{J}_i^T\boldsymbol{J}_i\Delta\boldsymbol{x}) \\
&+ \frac{1}{2}\rho''(s)(2e_i(\boldsymbol{x})^T\boldsymbol{J}_i\Delta\boldsymbol{x}+\Delta\boldsymbol{x}^T\boldsymbol{J}_i^T\boldsymbol{J}_i\Delta\boldsymbol{x})^2\\
\approx& \rho(s) + 2\rho'(s)e_i(\boldsymbol{x})^T\boldsymbol{J}_i\Delta\boldsymbol{x}+\rho'(s)\Delta\boldsymbol{x}^T\boldsymbol{J}_i^T\boldsymbol{J}_i\Delta\boldsymbol{x} \\
&+ 2\rho''(s)\Delta\boldsymbol{x}^T\boldsymbol{J}_i^Te_i(\boldsymbol{x})e_i(\boldsymbol{x})^T\boldsymbol{J}_i\Delta\boldsymbol{x}
\end{aligned}
$$
按照之前的思路,对上式求导并使其为 0,可得:
$$
\sum_i\boldsymbol{J}_i^T(\rho'(s) + 2\rho''(s)e_i(\boldsymbol{\boldsymbol{x}})e_i(\boldsymbol{x})^T)\boldsymbol{J}\Delta\boldsymbol{x} = -\sum_i\rho'(s)\boldsymbol{J}_i^Te_i(\boldsymbol{x})
$$
对比之前的矩阵 $\boldsymbol{J}^T\boldsymbol{J}\Delta\boldsymbol{x} = -\boldsymbol{J}_i^T\boldsymbol{e}(\boldsymbol{x})$ 可得,当我们使用了鲁棒核函数之后,只需要将各项残差的核函数的一阶二阶导数值计算出,再按照以上形式对信息矩阵和信息向量进行更新即可。
常用的鲁棒核函数
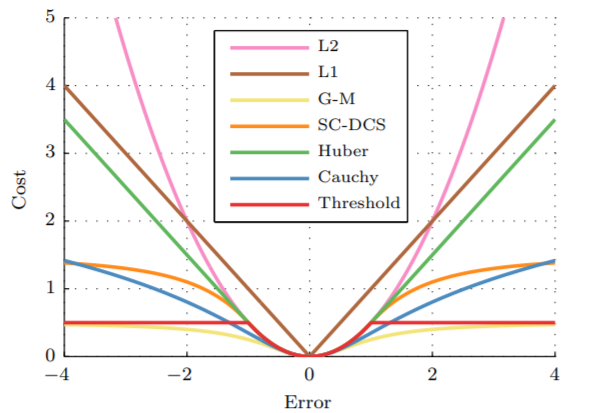
柯西鲁棒核函数:
$$
\begin{aligned}
\rho(s) &= c^2\log{(1+\frac{s}{c^2})}\\
\rho'(s) &= \frac{1}{1+\frac{s}{c^2}}\\
\rho''(s) &= -\frac{1}{c^2}(\rho'(s))^2
\end{aligned}
$$
其中,$c$ 为控制参数。当残差是正态分布,Huber c 选为 1.345,Cauchy c 选为 2.3849。不同鲁棒核函数的效果如下图所示: